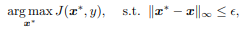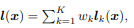나는 이전에 한 인공지능 교육 과정을 이미 수강한 바가 있다. 무슨 교육 과정인지 밝힐 수는 없지만 거기에서 얻은 게 너무 없고, 굉장히 실망스러워서 이 인공지능이란 길이 정녕 내 길이 맞는가에 대한 의구심과 시간을 날린 것에 대한 회의감을 갖고 있었고, 이 길을 아예 포기할까 하는 생각까지 갖고 있었다. 그래도 어디든 취직은 해야 하니까, 코딩하는 길로 취직을 하려면 코딩 테스트 준비는 필수적이었기에 프로그래머스 사이트에 들어갔다. 그러던 중 한 배너가 내 눈에 띄게 되었다.

K-Digital Training 프로그래머스 인공 지능 데브코스
평소에도 깔끔한 UI와 퀄리티 좋은 문제들, 강의를 제공해왔던 프로그래머스 사이트에서 인공지능 가르쳐준다고 하니 왠지 구미가 당겼다. 마침 나는 휴학 중이면서 졸업 예정자이기도 했기 때문에 신청 자격에 딱 걸쳐서 가능했었다. 문득 이전에 실패했던 경험이 있어서 두렵기도 했지만, 그 실패를 발판삼아 똑같은 실패를 반복하지 않으면 성공적으로 교육하고, 성장할 수 있지 않을까 하는 생각이 들게 되었고, 만약 이번에도 실패한다면 그때는 정말 이 길이 내 길이 아님을 깔끔하게 인정하고 미련 없이 다른 진로를 선택할 수 있을 것 같다는 확신이 들게 되어 정말 마지막이라 생각하고 도전을 하게 되었다.
그렇게 걱정 반, 기대 반으로 수업을 듣게 되었다. 그러나 걱정을 했던 것이 무색할 만큼 강의의 퀄리티가 상당히 높았고, 정말 웬만한 전공 강의가 부럽지 않을 정도로 전문적인 강의들이 학생들에게 제공이 되었다. 그 과정에서 내가 부족한 부분이 어떠한 부분인지도 파악할 수 있게 되어 좀 더 탄탄한 기반을 쌓는 데 큰 도움이 되었다고 생각한다. 그리고 어려운 부분에 대해선 slack 메신저를 이용하여 강사님께 바로 여쭤볼 수 있는 수도 있었기 때문에 모르는 것을 담아두고 끙끙 앓고 있는 것이 아니라 바로 해소할 수 있었다.
매주 목요일에는 zoom을 통한 특강이 열려 강의에 대한 추가적인 부분에 대해 듣기도 하고, 진로 고민에 대해 여러 조언을 들을 수 있는 시간도 가질 수 있었다. 특히 진로 특강은 너무나도 만족스러웠다. 실제로 현업에서 종사하는 분이었기 때문에 취직하면서 어떤 것을 준비해야 할지, 어느 부분이 중요한지에 대해서 깨닫고 더 체계적으로 취직을 대비할 수 있게 되었다.
팀 프로젝트는 아직 진행하고 있으나 운 좋게도 친절하고, 열정 넘치는 팀원분들을 만나 원만하고 즐겁게 진행할 수 있을 것이라는 기대를 품고 있다. 그 모습은 매달있는 먼슬리 프로젝트를 통해 확인할 수 있었다. 먼슬리 프로젝트도 해당하는 달에 핵심적으로 공부했던 부분을 이용한 프로젝트가 주로 진행이 돼서 그달에 공부한 내용을 전반적으로 회고하는 시간을 가질 수 있다. 이 프로젝트 자체도 굉장히 흥미롭고 재밌게 구성이 되어 7시간이라는 짧지 않은 시간 동안 진행되는 프로젝트임에도 불구하고 지루한 줄 모르고 임할 수 있던 것 같다. 그래서 자처해서 시간을 오버해서 프로젝트를 더 진행하기도 했다. (이는 팀원들의 열정도 있었기에 가능한 일이기도 했다!)
마지막으로 이 글을 읽고 데브코스에 지원할지 말지 고민하는 분들께 이렇게 말씀을 드리고 싶다. 꼭 한 번 도전해 보아라! 분명히 후회 없는 5개월이 될 수 있을 것이라 장담한다. 이렇게 질 좋은 전문성 있는 강의를, 학생의 고민을 자기 일인 것처럼 진심으로 걱정해주시고 챙겨주시며 코스가 원활히 진행되도록 늘 노력하시는 상냥한 매니저님, 프로젝트에 든든한 지원군이 되어주시는 멘토님, 모든 일에 열정적이고, 배울 점이 많은 팀원을 만날 수 있는 코스가 절대 흔치 않을 것이다. 게다가 국비 지원으로 무료이기까지 하니, 더더욱 망설일 필요가 없지 않을까? 어느 부분에서든 분명 배울 부분이 있을 코스이니 망설이지 말고 지원해 보시길 권해드리는 바이다.
'AI > KDT 인공지능' 카테고리의 다른 글
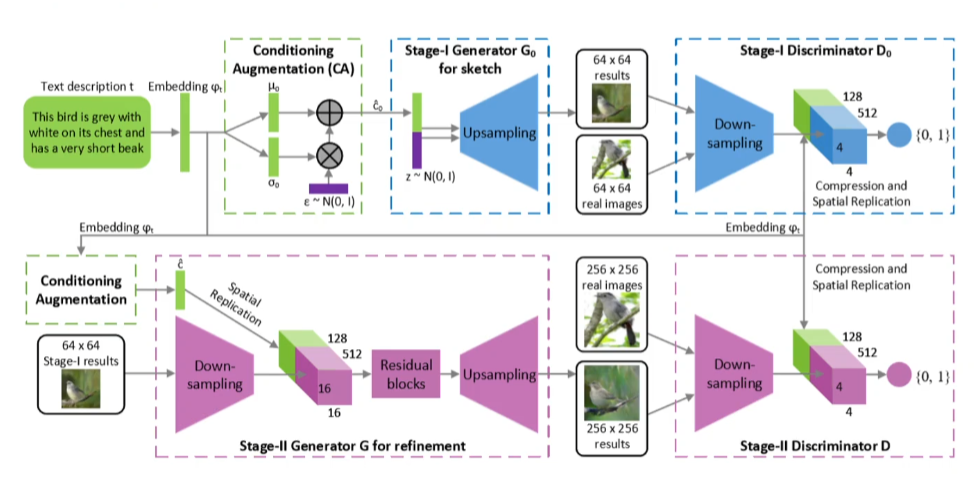
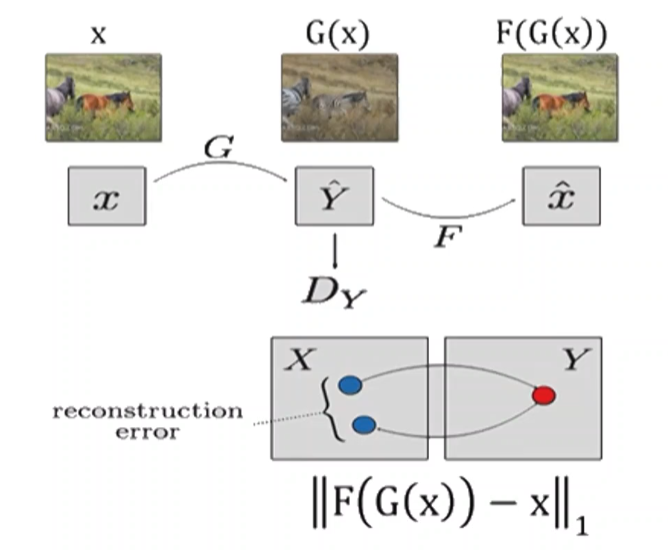
| [08/21] Black Box Attack (0) | 2021.08.21 |
|---|---|
| [08/13] 온라인 세션 (0) | 2021.08.13 |
| [08/10] GAN, Style Transfer (0) | 2021.08.10 |
| [08/09] Semantic Segmentation & Instance Segmentation (0) | 2021.08.09 |
| [08/05] Visual Recognition : Object Detection, Faster RCNN (0) | 2021.08.05 |