EDA ( Exploratory Data Analysis )
데이터 그 자체만으로 인사이트를 얻어내는 접근법 => 시각화 / 통계적 수치 / numpy, pandas
EDA process
- 분석의 목적과 변수 확인
- 왜 분석하려는지 목적을 명확히 하고, column들을 확인한다.
- 데이터 전체적으로 살펴보기
- 상관관계 파악
- NA가 없는지 파악
- 데이터 사이즈 파악
- 데이터의 개별 속성 파악하기
EDA with Example - Titanic
데이터 다운로드 : www.kaggle.com/c/titanic/data?select=train.csv
Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
- 분석의 목적과 변수 확인
목적 : 살아남은 사람들은 어떤 특징을 갖고 있었을지 확인
변수
- survival
- 생존했는지의 여부
- pclass
- 1등급석 / 2등급석 / 3등급석
- sex
- 남자 / 여자
- Age
- 연도기준 나이
- sibsp
- 형제 자매나 배우자가 몇 명이 타고 있었는가
- parch
- 부모와 자식이 얼마나 타고 있었는가
- ticket
- 티켓 번호
- fare
- 탑승객이 얼마를 내고 탔는가
- cabin
- 승무원 번호
- embarked
- 항구의 정보
- C / Q / S의 범주형 자료
2. 데이터 전체적으로 살펴보기
dataframe.describe()를 통해 수치형 데이터에 대한 요약을 확인할 수 있다.

dataframe.corr()을 통해 상관관계를 알 수 있다.

그러나, 상관성은 인과성이 아니다! 상관관계가 유의미하게 나왔다고 해서 반드시 둘 사이의 인과성이 존재한다고 말할 수는 없다
dataframe.isnull()을 통해 결측치를 확인할 수 있다.
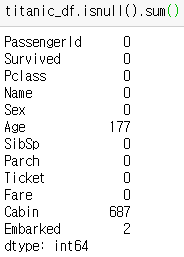
결측치에 대한 부분은 어떻게 바라볼지에 대해서도 생각해야하기 때문에 결측치에 대한 처리도 중요하다.
3. 데이터의 개별 속성 파악하기
(1) 생존자와 사망자 수 확인
value_counts() 이용

sns.countplot() 이용

(2) Pclass에 따른 인원 파악
groupby 후 count()

각 Pclass 마다의 생존자 인원은?

각 Pclass 마다 생존 비율은?

히트맵을 통해서도 확인하기

=> Pclass가 좋은 등급이면 등급일수록 생존 확률이 높구나!
(3) Sex
성별에 따른 생존자 수 확인

catplot()을 이용하기

=> 남성보다 여성의 생존자가 더 많은 것을 확인할 수 있다.
(4) Age (결측치 존재)
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
sns.kdeplot(x=titanic_df[titanic_df.Survived == 1]['Age'], ax=ax)
sns.kdeplot(x=titanic_df[titanic_df.Survived == 0]['Age'], ax=ax)
plt.legend(['Survived','Dead'])
plt.show()

=> 약자(어린이, 노인)의 경우 더 많이 생존한 것을 확인할 수 있다.
4. 데이터 복합 요소에 대해 살펴보기
(1) 성별 + Pclass vs Survived
sns.catplot(x="Pclass", y="Survived", hue = "Sex", kind="point", data = titanic_df)
plt.show()
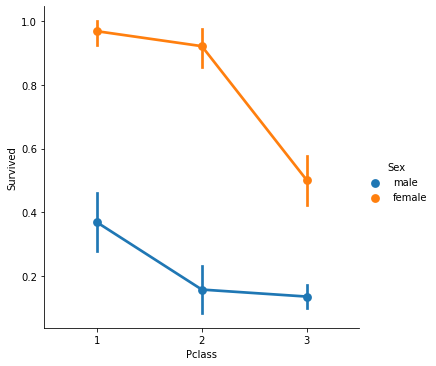
=> Pclass가 1과 2이면서 여성이었던 사람들은 Survived의 추정치가 높았고, Pclass가 2와 3이면서 남성이었던 사람들은 Survived의 추정치가 0.2정도로 매우 낮은 것을 확인할 수 있다.
(2) Age + Pclass
## Age graph with Pclass
titanic_df['Age'][titanic_df.Pclass == 1].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass == 2].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass == 3].plot(kind='kde')
plt.legend(['1st class','2nd class','3rd class'])
plt.show()

=> class가 더 높은 class일수록 나잇대가 높아진다는 것을 확인할 수 있다.
'AI > KDT 인공지능' 카테고리의 다른 글
| [05/17] Web Application with Django (0) | 2021.05.17 |
|---|---|
| [05/12] EDA mini project (0) | 2021.05.12 |
| [05/11] AWS를 활용한 인공지능 모델 배포 (0) | 2021.05.11 |
| [05/10] Web Application with Flask (0) | 2021.05.09 |
| [05/06] Matplotlib (0) | 2021.05.06 |