CTC Dynamic Programming
단순히 학습이 끝난 마지막 지점에서 Greedy하게 x spectogram이 나왔을 때 argmax해서 나온 path를 선택하는 것이 적절하지 않은 방법이 아니고, relavant한 path가 많은데 좋은 path를 찾는 방법을 모두 연산하자니 가능한 path가 너무 많아진다는 문제가 발생한다.
CTC의 속성에 따라서 valid alignments는 marginalize했을 때 Y label이 나와야 한다.
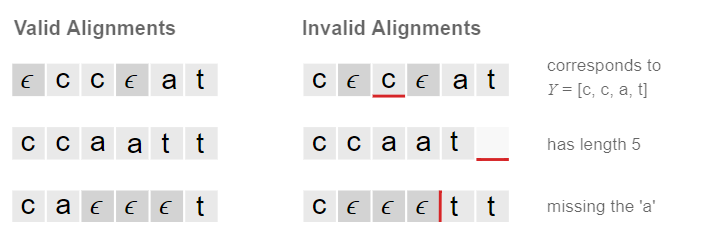
이 성질을 생각하며 아래 그림을 확인한다.
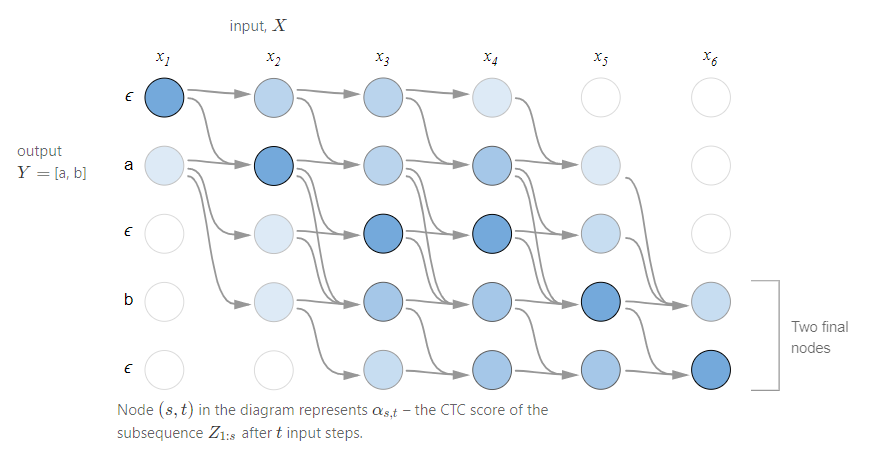
데이터에 의하면 사람들은 [a,b]라고 발음하고, 우리가 알고 있는 모든 전체 집합 상에만 계속 묵음이 존재한다고 나오는 것이다. 그렇다면 데이터를 통해 학습을 하면 적어도 4번에는 a가 나온다는 것이다. data의 distribution 상 5번이나 6번에는 묵음이 존재하지 않다는 것이다.
모든 path를 생각해보면 앞서 정의했던 CTC characteristic에 의해 어느 정도 path는 고정이 되어 있다. 우선, component의 output length에 맞게 단어가 등장해야 하고, 단어에 의해 순서가 어느 정도 강제되며, epsilon도 나와야하는 label이 존재하지 않는데 epsilon이 나올 순 없으며, legnth가 input length에 맞춰 발음되어야 한다는 것이 rule이다. 이 rule에 따르면 모든 path가 존재한다고 해도 가능한 path는 한정적이게 된다. 이를 수학적으로 표현한 식은 다음과 같다.
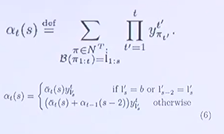
시간 t에서 모든 paths의 시퀀스 1부터 p까지의 확률이다.

두 개의 case로 recursive하게 form을 설명할 수 있다.
결론적으로, 기본 데이터에 대해 가장 relevant한 path는 마지막 time sequence의 alpha값으로 설명할 수 있다고 말하고 있다.
CNN쌓고 RNN 쌓아서 encoding 잘 된 애를 fully connected 통과한 후 거기에 맞춰 softmax 시켰더니 time sequence 별로 probability distribution이 나오고 이것이 CTC에 의해 어떤 relevant한 path를 찾을 수 있다!
이 다음에 나온 모델이...
LAS
Attention을 사용해보자!
Listener (Encoder) : BLSTM을 Pyramidal 형식으로 붙여 쓴다. = pBLSTM
왜 Pyramidal하게 사용하는가? 왜냐하면 pBLSTM 1개당 연산속도를 2배로 줄여주기 때문.
LAS는 이전 Step에서 디코딩된 정보를 받아 현재 Input Sequence와 결합해 다음 Sequence를 예측하는 구조로 Decoding한다. 이런 방식을 Auto-regressive 방식이라고 한다.
디코딩의 output이 다음 디코더를 예측하는 대 사용하는 Auto regressive한 형태를 띄고 있다!
이후의 논문들...
Towards End-to-End Speech Recognition with Recurrent Neural Networks
Joint CTC(CTC+LAS)
Korean speech recognition using deep learning
'AI > 음성 인식' 카테고리의 다른 글
| [토크ON세미나] 딥러닝 기반 음성인식 기초 4강 - 음성인식 알고리즘 I - CTC - Data augmentation (0) | 2020.10.19 |
|---|---|
| [토크ON세미나] 딥러닝 기반 음성인식 기초 3강 - Audio Classification & Tagging (0) | 2020.10.19 |
| [토크ON세미나] 딥러닝 기반 음성인식 기초 2강 - 딥러닝 기초 II (0) | 2020.10.19 |
| [토크ON세미나] 딥러닝 기반 음성인식 기초 1강 - 딥러닝 기초 (0) | 2020.10.16 |