PDF : Probability Density Function (확률 밀도 함수) 수식 기호 : p_z
Sample drawn from the PDF 수식 기호 : z ~ p_z
영상을 만들어내는 PDF를 알고 있으면 영상을 생성할 수 있다.(p_data) PDF값이 큰 sample을 생성하면 됨.
그러나, PDF를 구하는 것이 불가능. 그래서 나온 것이 GAN
GAN(Generative Adversarial Network)
Generator : 가짜 돈(데이터)을 만들어 속이는 역할
Discriminator : 가짜 돈인지 실제 돈인지 가리는 것
Generator가 생성한 가짜 돈을 Discriminator가 구분해내지 못했을 때 모델이 다 학습을 마쳤다고 볼 수 있다.
구조
노이즈 -> Generator -> 가짜 -> Discriminator -> 가짜 or 진짜 ↑ 진짜↗ | |__________________________| 피드백
노이즈 : Input data. 가우시안 노이즈. 이 노이즈에 따라 다른 결과값을 도출하게 된다. z_1, z_2, ..., z_n
Generator : 매핑 함수의 역할을 할 수 있는 Generator 생성 G(z_1), G(z_2), ..., G(z_n) 이 Generator도 Convolution Network였다. 이 때 Fractionally-strided convolution 연산을 시행하였다.
가짜 데이터 : G(z) ~ p_data
Discriminator : 진짜 데이터가 들어오면 높은 값, 가짜 데이터가 들어오면 낮은 값을 반환시키는 것. D(x) 예전의 D는 그저 Convolution Network였다.
Cost Function 하나의 영상에 대한 GAN Cost function여러 개의 영상에 대한 GAN Cost function(2)
여러 개의 영상에 대한 GAN Cost function에서 기댓값은 실제로 구할 순 없는 개념 상의 수식이다. 이를 사용하기 위한 방법으로는 많은 데이터를 쓰는 것이 가장 쉬운 방법이다.
아래는 Cost function을 최적화시킨 것이다.
바로 위에 식에서 D와 관련있는 부분은 뒷 부분 (E_z~p_z(z)[log(1-D(G(z)))]이다. 우리는 D(*)에 G(z)가 들어갔을 때 높은 값을 내길 원하기 때문에(=Generator가 만든 가짜 데이터를 진짜라고 인식하는 비율이 크길 원하기 때문에) 결국, 1-D(G(z))는 낮은 값이길 원하니 이 전체의 값을 최소화하는 G를 구하고 싶은 것이다.
D에서는 Grandient Descent가 아닌 Ascent. 값이 증가하는 방향으로 Gradient를 Update시켜야 한다.
G에서는 Gradient Descent로 Gradient Update.
수많은 영상의 결과에서 얻은 Loss에 대한 평균값에 대해 학습시키는 것이기 때문에 좋지 않은 결과를 도출해내곤 했다. Image colorization에선 정확하지 않은 색을, Super resolution에선 선명하지 않은 영상을 반환했다.
Universal Loss
위의 Fixed Loss의 단점을 보완하기 위해서 사용한 것이 Universal Loss이고 실제로 성능이 굉장히 좋아진 것을 확인할 수 있다고 한다. 이 때에도 GAN이 사용이 된다.
L2대신 Discriminator를 사용한다. 이 Discriminator 자체를 Loss로 둔다. 이것과 위에서 살펴본 GAN과의 차이는 Input에 있다. 아까는 임의의 노이즈를 준 반면, 이 때의 Input으로는 하나의 영상을 주게 된다. 그 외 나머지는 다 같다. 이 때의 GAN을 Pix2Pix라고 한다.
PatchGAN : Patch 단위로 Discrminate한다. 한 Patch가 어느 정도 영역을 보고 있는지에 대해 나타나있는 것이 Receptive Field
Pix2Pix Loss 함수
뒤에 부분인 λL_(L1)(G)는 Fixed Loss이다. 수많은 영상에 대해서 만족스러운(평균을 낸) Loss값을 도출해내야 하므로 뒤에 수식만 사용하여 Loss를 구하면 아까 단점으로 언급했던 바와 같이 fade된(뿌얘진/노이즈가 낀) 영상이 반환된다. 그럼 앞에 부분 수식만 쓰면 되는 것 아닌가? 이 또한 아니다. 가령, 흑백 영상을 컬러 영상으로 변환한다고 하자. 이 때 앞에 수식은 Input으로 주어진 흑백 영상을 고려하지 않고 그저 컬러인 영상만을 만족하는 영상을 반환하게 된다. 즉, Input과 완전히 다른 그저 색깔만 입혀진 영상을 내는 것이다. 그래서 뒤의 L1 Loss를 주어 원래의 Input과 유사한 형태의 결과를 반환할 수 있도록 하는 것이다. 이처럼 두 수식이 서로 보완을 해주며 작동을 해야 더 좋은 성능을 나타나게 된다. L_c에서 c는 conditional이다. 아까 본 GAN에서 D( * ) 함수와 G( * ) 함수에 들어가는 파라미터가 달라졌다.
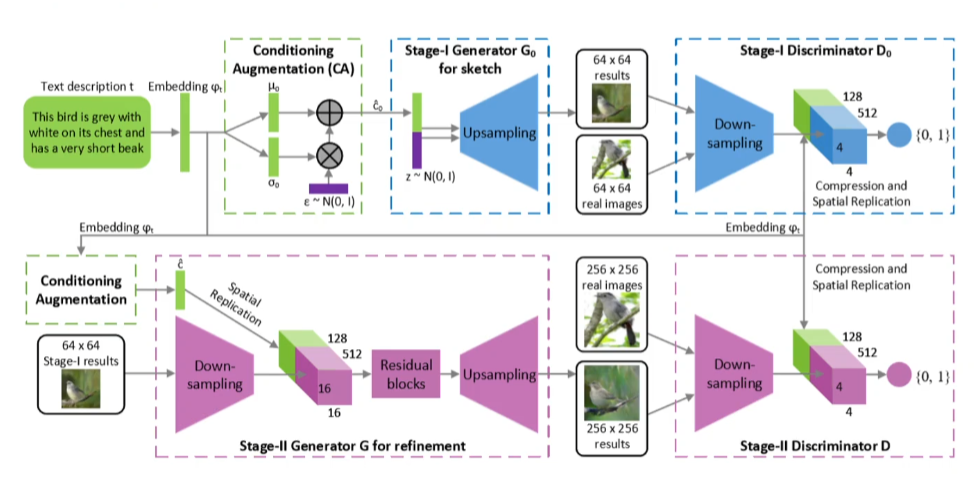
Pix2Pix Structure
가짜 데이터를 학습시킬 땐, 원영상 x와 변환하고자 하는 목표 영상 y 쌍 {x, y}가 필요하다. 이런 데이터를 많이 준비해 학습시키면 된다.
Conditional GAN
앞서 살펴본 Pix2Pix도 Conditional GAN에 포함된다. Conditional GAN은 그 말마따나 GAN에 추가적인 조건(condition)을 더한 것이다.
Conditional + Stack GAN
Text를 임베딩하여 하나의 벡터로 만들어 활용하는 것이 Stack GAN으로, 이 때 나온 vector를 condition으로써 적용시킬 수 있다. StackGANConditional+Stack GAN
Progressive GAN
4x4로 downsampling한 영상만 보여주며 이와 구분이 안 되는 4x4 가짜 영상을 만들게끔 한다. 이를 하나의 입력으로 넣어 이 때의 8x8 영상을 만들도록 한다. 이 과정을 반복하여 나중에 고해상도의 1024x1024 영상까지 만들어내도록 한다. 굉장히 좋은 퀄리티의 영상을 얻어낼 수 있다. Progressive GAN
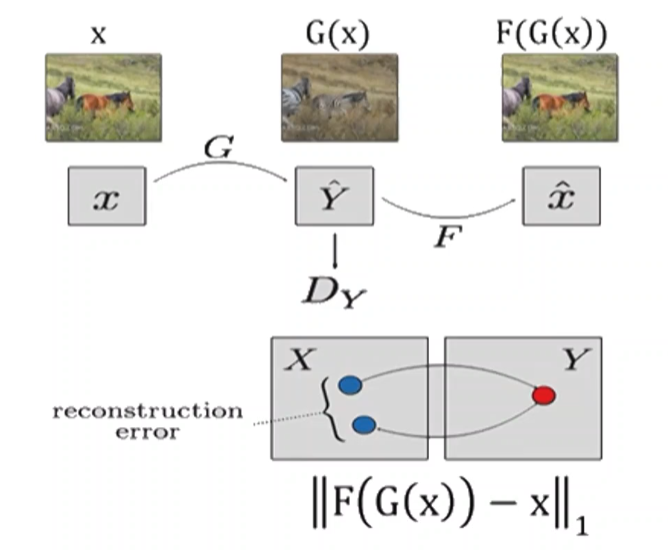
CycleGAN
Pix2Pix같은 경우 쌍으로 존재할 때 학습이 가능했다. 그러나 우리는 Unpaired된 쌍도 유사한 feature가 되도록 변화하는 작업을 하고 싶은 경우가 생길 수 있다.(가령, 말을 얼룩말로 변환한다거나...) 이를 위해 만들어진 것이 CycleGAN
Figures from the tutorial of Alexei Efros, UC Berkeley at ICCV 2017 Tutorial on GANs
여기선 G와 F라는 두 개의 함수를 학습시킨다. min(||F(G(x)0 - x||)값을 구하게 된다. x와 F(G(x))와 비슷하도록 하는 제약조건을 주면 G(x)도 비슷할 것이라는 개념을 활용하는 것이다. 당연히 G(x)로 변환한 F(G(x))가 원래의 원본과 완전히 다르면 제대로 학습이 안 됐다고 볼 수 있을 것 이다.
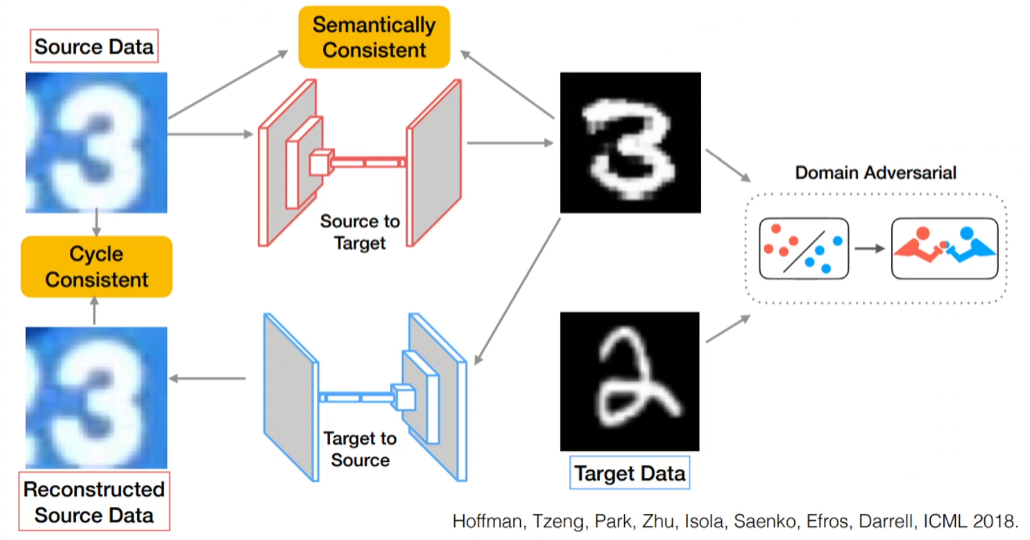
CyCADA
CycleGAN에 Semantically Consistent만 붙인 것이다. the tutorial of Judy Hoffman at ICCV 2019
위에서 Domain Adversarial이 Discriminator다.
Domain Adaptation
이해를 아직 못해서 제대로 정리 못했습니다 이 부분은 넘어가주셨으면 합니다.
GAN에서 쓰이는 adversarial loss가 Domain Adaptation에 중요한 요소 기술이 되고 있다.
모아놓은 데이터에 Bias가 있을 수 있다. 이러면 Low resulution, Motion Blur, Pose Variety와 같은 문제가 생기면 제대로 인식이 되지 않을 수 있다. 그러면 그러한 케이스를 다 가진 데이터를 모으면 되지 않은가, 그것은 비용이 너무 비싼 것이 문제이다. 그래서 나온 것이 Domain Adaptation이다. 깨끗한 영상에 대해 학습을 했지만, 비교적 저품질의 input이 들어와도 제대로 인식할 수 있게끔 해준다.
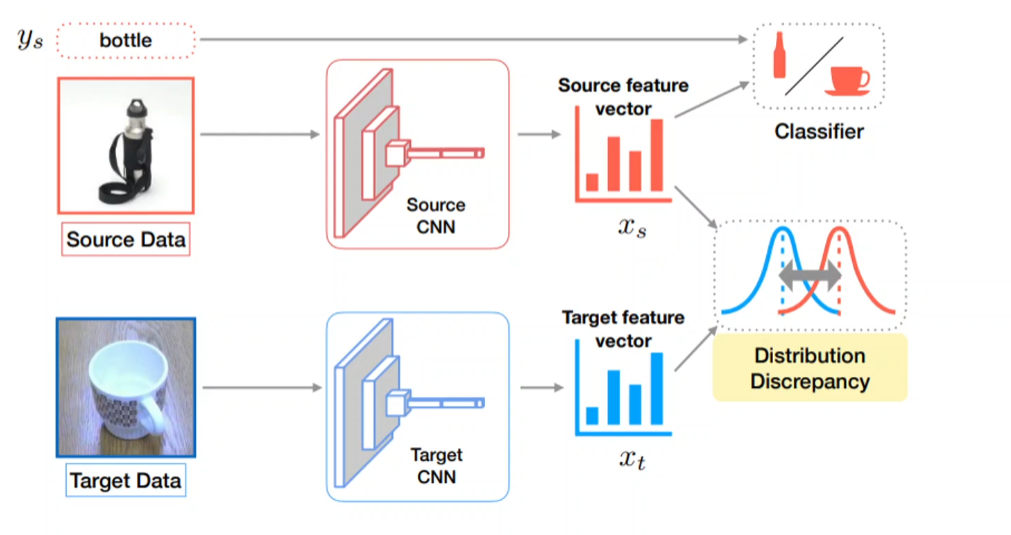
Deep Domain Adaptation
the tutorial of Judy Hoffman at ICCV 2019
각 feature vector의 분포(직접 만들 순 없고 개념적인 것)에 차이가 있을 것이라고 본다. 이 분포 간 차이를 측정하기 위한 도구로 Max Mean Discrepancy가 있다.(KL divergency라는 것도 있다고 한다..!) 이 차이를 줄여야 한다.
Classification 학습Maximize the confusion of domain classifier
Style Transfer (스타일 전이)
content 영상에 style 영상의 style을 전이하는 것이 목표이다.
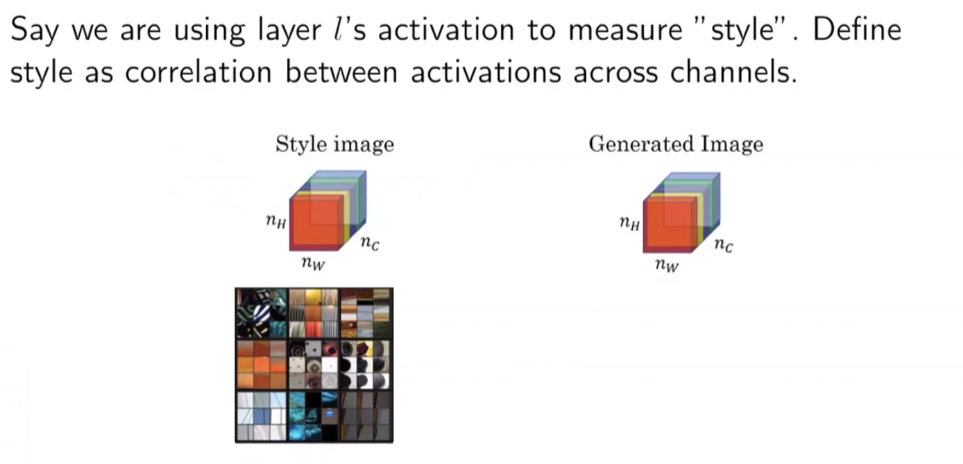
Style 정의
Slide Credit : Andrew Ng
스타일은 채널 간 activation 사이의 상관관계라고 정의한다.