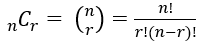Git
분산 버전관리 시스템이다.
git 설치 링크 : git-scm.com/
Git
git-scm.com
해당 운영체제에 맞는 Git을 설치하면 된다.
Git 시작하기
- git init
- 로컬 저장소 생성
- 현재 작업중인 디렉토리를 git 저장소로 지정할 수 있다.

vim을 통해 initialize한 저장소에 "Hello World!"문을 출력하는 example.py 파일을 생성한다.

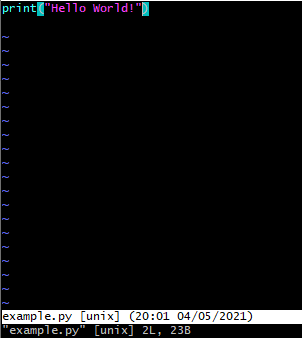
- git status
- git 저장소의 상태를 확인하는 것

example.py 파일은 다음 commit에 반영이 안 된다는 문구가 나오게 된다. 이 파일을 커밋에 반영할 파일로 지정해보자.
- git add
- 다음에 commit을 무엇을 남길지 지정하는 행위

example.py 파일을 unstaged 상태에서 staged 상태로 바꾼다.
즉, example.py을 다음 commit에 넣겠다 선언하는 것이다.
- git commit
- add된 것들을 다음 commit으로서, snapshot으로 남긴다

snapshot에 대한 메세지를 담아 commit한다. 메세지를 담으려면 git commit 뒤에 -m을 붙이고 남길 메세지를 작성하면 된다.
- git log
- commit을 확인한다.

Git의 Branch
코드의 흐름을 분산, 가지치기 하여 각각 독립적인 환경에서 코드를 수정해나갈 수 있도록 해주는 것이 Branch이다.
- git branch <branch_name>
- git branch를 생성하는 명령어이다.
- branch를 생성하기 전에는 Default로 master라는 branch가 기본적으로 생성된다.

이전과 다르게 master와 develop이라는 두 개의 branch가 있는 것을 확인할 수 있다.
- git checkout <branch_name>
- branch_name의 branch로 전환해주는 명령어이다.

현재 branch가 develop을 가리키고 있음을 확인할 수 있다.
이 전환된 branch 상태에서 example.py 파일에 변화를 줘보자.

"Hello World in Develop branch!"라는 문장을 example.py에 추가했다.
그 후 상태를 확인하면

다음과 같이 변경 사항이 commit에 반영되지 않았다는 상태를 확인할 수 있다.
이 example.py를 commit하도록 하자.

master branch에서 작업한 commit 내역과 develop branch에서 작업한 commit 내역이 따로 저장되어 있는 것을 확인할 수 있다. 다시 master branch로 돌아가게 된다면 이 example.py는 어떻게 되어 있을까?

develop branch에서 작업한 변경 사항이 master branch에는 반영되어 있지 않은 것을 확인할 수 있다.
이 때 master branch가 중심 branch이기 때문에
develop의 변경 사항을 master에도 병합을 해야 할 때가 있을텐데 그렇게 하려면 어떻게 해야 할까?
- git merge <branch_name>
- 현재 작업중인 Branch를 원하는 Branch에 병합할 수 있다.


develop과 master가 같은 commit을 가지게 되는 것을 확인할 수 있다.

실제로 exmaple.py 파일을 확인해보면 develop branch에서 변경했던 사항이 master branch에도 잘 반영되어 있는 것을 확인할 수 있다. 이를 통해 Fast forward 방식의 merge가 잘 이루어졌음을 알 수 있다. 이외에도 merge 방식은 다양한 방식이 있다.
- git branch -d <branch_name>
- branch를 삭제하는 명령어이다.

branch가 잘 삭제되었음을 확인할 수 있다.
Github
지금까지 살펴봤던 git은 로컬 저장소고 원격 저장소는 이 git과 상호작용하면서 분산 시스템을 구축하게 된다.
다양한 원격 저장소가 있지만 그 중 Github를 사용해보도록 하겠다.
github의 계정을 생성했으면 다음과 같이 new repository를 생성한다.

생성했으면 로컬 저장소와 원격 저장소를 연결해주도록 하자.
- git remote add <별칭> <원격 저장소 주소>
- 로컬 저장소와 원격 저장소를 연결해주는 명령어이다.

이렇게 연결해주면 원격 저장소에 로컬 저장소에서 작업하고 있던 정보들을 전달해줄 수 있다. 그 전에 github에서는 중심 branch의 이름을 main이라는 이름으로 사용하기 때문에 git의 master branch의 이름을 다음과 같이 main으로 변경해주어야 한다.

- git push <remote_repo_name> <branch_name>
- 로컬 저장소에서 작업하고 있던 정보들을 원격 저장소에 반영하는 명령어이다.

push가 이뤄지고 난 후 연결한 원격 저장소로 가보면


다음과 같이 변경사항이 잘 반영되었음을 확인할 수 있다.

github 원격 저장소 우상단에 있는 Fork를 하면 다른 사람의 원격 저장소를 자신의 원격 저장소로 복사 - 붙여넣기 할 수 있다.

이 원격 저장소에 있는 내용을 바탕으로 로컬 저장소에서 작업을 진행해보도록 하자.
- git clone <remote_repo><alias>

다음과 같이 git clone을 통해 원격 저장소에 있는 material을 로컬 저장소로 가져올 수 있게 된다.
'AI > KDT 인공지능' 카테고리의 다른 글
| [05/06] Matplotlib (0) | 2021.05.06 |
|---|---|
| [05/05] 데이터 다루기 - Pandas (0) | 2021.05.05 |
| [05/04] Python으로 데이터 다루기 - Numpy (0) | 2021.05.04 |
| [05/03] 인공지능 수학 - 추정, 검정, 엔트로피 (0) | 2021.05.03 |
| [04/29] 인공지능 수학 - 확률과 확률분포 (0) | 2021.04.29 |