부동산 회사에 막 고용된 데이터 과학자라 가정 후 예제 프로젝트를 처음부터 끝까지 (End-to-End) 진행하자. 주요 단계는 다음과 같다.
- 큰 그림을 본다. (look at the big picture)
- 데이터를 구한다. (get the data)
- 데이터로부터 통찰을 얻기 위해 탐색하고 시각화한다. (discover and visualize the data to gain insights)
- 머신러닝 알고리즘을 위해 데이터를 준비한다. (prepare the data for Machine Learning algorithms)
- 모델을 선택하고 훈련시킨다. (select a model and train it)
- 모델을 상세히 조정한다. (fine-tune your model)
- 솔루션을 제시한다. (present your solution)
- 시스템을 론칭하고 모니터링하고 유지 보수한다.(launch, monitor, and maintain your system)
큰 그림 보기
풀어야 할 문제 : 캘리포니아 인구조사 데이터를 사용해 캘리포니아의 주택 가격 모델을 만든다.
이 모델이 전체 시스템 안에서 어떻게 사용될 지 이해하는 것이 중요하다.
중요한 질문 : 현재 솔루션은? 전문가가 수동으로? 복잡한 규칙? 머신러닝?
문제 정의
- 지도학습(supervised learning), 비지도 학습(unsupervised learning), 강화학습(reinforcement learning) 중 어떤 경우에 해당하는가? - 지도학습이다.
- 분류문제(classification)인가 아니면 회귀문제(regression)인가? - 회귀문제이다.
- 배치학습(batch learning), 온라인학습(online learning) 중 어떤 것을 사용해야 하는가? - 배치학습을 사용해야 한다.
성능측정지표(performance measure) 선택
평균제곱근 오차(root mean square error (RMSE))

- m : 데이터셋에 있는 샘플 수
- x^(i) : i번째 샘플의 전체 특성값의 벡터(vector)
- y^(i) : i번째 샘플의 label(해당 샘플 기대 출력값)

- X : 데이터셋 모든 샘플의 모든 특성값(features)을 포함하는 행렬(matrix)
- h : 예측함수(prediction function). 하나의 샘플 x^(i)에 대해 예측값 yhat^(i)=h(x^(i))를 출력함.
- RMSE(X, h) : 모델 h가 얼마나 좋은지 평가하는 지표, 또는 비용함수(cost function)
데이터 가져오기 (Get the Data)
데이터 구조 훑어보기
housing = load_housing_data()
housing.head()

각각의 행은 한 구역(지역)을 나타낸다.
- longtitude / latitude : 위치 정보(경도와 위도)
- housing_median_age : 해당 지역의 집들을 기준으로 연도를 조사한 중간값
- total_rooms : 지역 전체 방의 수
- etc
housing.info()

총 20640개의 행들로 구성되어 있음을 알 수 있다. 이 중 total_bedrooms 열에 대해서는 167개의 missing value(null data)가 존재함을 알 수 있다.
마지막 ocean_proximity는 유일하게 Dtype이 'object'인데 이는 csv 파일에서 읽었기 때문에 text 데이터(범주형 필드)라는 것을 유추할 수 있다.
이 데이터들을 히스토그램으로 분석해보자.
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
save_fig("attribute_histogram_plots")
plt.show()

median income의 x축 값같은 경우 0, 2, 4...로 굉장히 작은 값들로 이뤄져있음을 알 수 있다. 살짝 이상함을 느낄 수 있을 것이다. 이에 대한 정확한 단위를 데이터를 제작한 사람에게 문의하고, 확인하여야 한다.
또, 가끔 이상하게 뒷 쪽에 값이 몰려있는 부분이 있다. 이렇듯 이상할 수 있는 것은 특정값 상위값에서 제한을 둔 것이라고 생각할 수 있을 것이다. 이런 부분도 데이터를 만든 사람에게 문의하고, 확인할 수 있도록 하여야 한다.
데이터로부터 통찰을 얻기 위해 탐색하고 시각화한다.
테스트 데이터셋 만들기
하나의 데이터셋을 훈련 / 테스트용으로 분리하기
import numpy as np
np.random.seed(42)
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
len(train_set), len(test_set)

총 20640개의 데이터에서 16512개의 데이터가 훈련용, 4128개의 데이터가 테스트용으로 임의로 뒤섞여 분리되었다.
그러나 위 방법에는 문제점이 하나 있다. 바로, 테스트 데이터를 뽑아내는 작업을 한 번만 하게 되는 것이 아니라 여러 번 하게 될 가능성이 높다는 것이다. 예를 들어 새로운 데이터가 들어왔을 때 다시 한 번 훈련 데이터와 테스트 데이터로 나누고 싶은 경우가 생길 수도 있는데 이 때, 또 위의 함수를 사용한다면 이전 훈련 데이터에 속하던 데이터들이 테스트 데이터로 속하게 될 수도 있고 반대의 경우가 생기게 될 수도 있을 것이다. 그러나 우리가 원하는 것은 한 번 테스트 데이터였던 데이터들은 계속 테스트 데이터로 남는 것이다.
이를 해결하기 위해선 각각 샘플마다 식별자(identifier)를 사용해 분할한다!
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
test_set_check에서 식별자가 들어왔을 때, crc32 함수를 해싱 함수로 사용하고, & 기호는 bitwise and function이다. 위의 0xffffffff 숫자는 (2^32)-1이다. 저렇게 하게 되면 2^32으로 나눈 나머지 값이 되는 것이다. 그래서 식별자가 들어오면 이 식별자를 가진 데이터가 테스트 데이터에 속하는지 속하지 않는지 True or False를 반환하게 된다.
이제 식별자가 될 column을 추가해주어 보도록 하자.
# 인덱스를 id로 추가
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
위의 방법에는 문제점이 있다. 왜냐하면 id가 되려면 id는 늘 일정히 유지를 해야 하는데 행 번호를 id로 쓰게 되면 나중에 데이터베이스가 update 되어 몇몇 데이터들은 사라질 수도 있고, 중간에 삽입이 될 수도 있고(이런 문제를 방지하기 위해선 늘 새로운 데이터는 뒤에 넣어주어야 한다는 제약이 생기게 되기도 한다.), ... 그렇게 되면 행 번호가 바뀌게 될 수도 있기 때문이다.
그래서 id를 만드는 데 안전한 feature들을 사용하도록 해야 한다.
# 경도와 위도를 사용한 식별자 생성
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
train_set.head()
위 데이터에서 가장 unique한 데이터인 지리적 속성을 사용해서 식별자를 생성할 수 있게 된다. id는 다음과 같은 새로운 column의 형태로 생성된다.

우리의 scikit-learn에서 친절하게도 기본적으로 제공되는 데이터분할 함수가 있다.
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
위 우리가 생성한 함수에서처럼 20퍼센트의 데이터를 test 데이터로 사용할 것이고, 훈련 데이터는 train_set에, 테스트 데이터는 test_set에 저장되게끔 할 것이다. 결과는 직접 생성한 함수와 같다. 그러나 이렇게 하게 되면 우리가 식별자를 잘 나눠주었음에도 불구하고 문제가 생길 수 있다. 예를 들어 얘기하자면, 투표가 있으면 남성과 여성의 투표 전체적 비율이 훈련 데이터와 테스트 데이터에도 잘 보존이 될 수 있도록 해야 공평한 테스트가 이뤄진다고 볼 수 있을 것이다. 그래서 이러한 경우를 위해서 우리는 계층적 샘플링(stratified sampling)을 한다.
위 데이터의 경우에는 가장 중요한 특성인 'median income'의 분포가 훈련 데이터, 테스트 데이터에 잘 나타날 수 있도록 해보겠다.
housing["median_income"].hist()

위 데이터들을 그룹으로 나눠 연속적인 데이터에 범주형(categorical) 데이터로 변환해보도록 하자.
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
housing["median_income"].hist()

이렇게 중요한 데이터를 범주형 데이터로 변환한 후에 이를 이용해 계층적 샘플링을 하도록 하자. 이를 직접 구현할 수 도 있겠지만... 아까 말했다시피 친절한 scikit-learn에서는 이 계층적 샘플링에 대해서도 이미 구현이 되어 있다!!!
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
housing["income_cat"].value_counts() / len(housing)
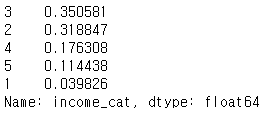
strat_train_set["income_cat"].value_counts() / len(strat_train_set)

strat_test_set["income_cat"].value_counts() / len(strat_test_set)

완전히 똑같진 않지만 원래의 데이터와 훈련 데이터, 테스트 데이터가 계층(우리가 median_income을 범주형 데이터로 변환한 새로운 데이터인 income_cat)에 따라 똑같진 않지만 매우 비슷한 비율로 잘 분포되어 나눠졌음을 확인할 수 있다!
즉, 계층적 샘플링을 하게 되면 우리가 중요하다고 생각하는 특성에 관해서 그 분포를 그대로 가져갈 수 있게 된다.
데이터 이해를 위한 탐색과 시각화
지리적 데이터 시각화
housing.plot(kind="scatter", x="longitude", y="latitude")
save_fig("bad_visualization_plot")

밀집된 영역 표시
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
save_fig("better_visualization_plot")

더 다양한 조건을 표시해보자.
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7), # 원의 반지름 => 인구
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True, # 색상 => 가격
sharex=False)
plt.legend()
save_fig("housing_prices_scatterplot")

지도 위에도 직접 나타내보자!!!
# Download the California image
images_path = os.path.join(PROJECT_ROOT_DIR, "images", "end_to_end_project")
os.makedirs(images_path, exist_ok=True)
#DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
DOWNLOAD_ROOT = "https://ko.wikipedia.org/wiki/%EC%BA%98%EB%A6%AC%ED%8F%AC%EB%8B%88%EC%95%84%EC%A3%BC#/media/%ED%8C%8C%EC%9D%BC:USA_California_location_map.svg"
filename = "california.png"
#나 같은 경우는 주석친 교수님이 주신 사이트에 캘리포니아 지도 이미지가 나타나지 않아 아래의 이미지를 따로 다운로드 받아 사용하였다...
import matplotlib.image as mpimg
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar()
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
save_fig("california_housing_prices_plot")
plt.show()

상관관계(Correlations) 관찰하기
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
# from pandas.tools.plotting import scatter_matrix # For older versions of Pandas
from pandas.plotting import scatter_matrix
# 특성 몇 개만 살펴봄
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
save_fig("scatter_matrix_plot")

여기서 median_house_value와 median_income 사이에서의 상관관계를 살펴보면
housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1)
plt.axis([0, 16, 0, 550000])
save_fig("income_vs_house_value_scatterplot")

50만불에서의 데이터가 많이 모여있다는 사실을 알 수 있다. 우리는 이를 통해 집 값이 50만 불 이상으로 넘어가는 값들에 대해서는 딱 50만 불로 정제를 했을 것이라는 사실을 유추할 수 있다. 이런식으로 비정상적으로 보이는 데이터 같은 경우는 가능하면 traininig data에서 제거시켜주는 것이 모델 학습에 더 좋은 결과를 나타내어 줄 것이다.
우리는 다양한 특성들을 조합해서 실험을 해볼 수 있다.
가령, 가구당 방 개수가 평균적으로 몇 개일지,
침대방의 비율은 얼마나 될지,
가구당 인원은 얼마나 되는지 등에 대해서 있는 특성을 조합해 새로운 특성으로써 만들어 사용할 수 있다.
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
이렇게 새롭게 만들어 낸 특성으로 다음과 같은 새로운 사실을 유추해 낼 수 있을 것이다.
bedrooms per room같은 경우에는 하나의 집에서 침실이 차지하는 비율인데 집이 당연히 크면 클수록 침실로 쓸 방들은 제한이 되고, 다른 방들의 비율이 더 늘어날 것이다.
이 외에도 또다른 새로운 사실들을 많이 유추해 낼 수 있을 것이다.
이제는 실제로 모델에 데이터를 학습시키기 위하여 조금 더 데이터를 정제하는 작업을 거쳐보도록 하겠다.
데이터는 수동으로 변환하는 것보다 자동으로 변환하는 것에 대한 장점은 다음과 같다.
- 새로운 데이터에 대한 변환을 손쉽게 재생산(reproduce)할 수 있다.
- 향후에 재사용(reuse)할 수 있는 라이브러리를 구축할 수 있다.
- 실제 시스템에 가공되지 않은 데이터(raw data)를 알고리즘에 쉽게 입력으로 사용할 수 있도록 해준다.
- 여러 데이터 변환 방법을 쉽게 시도해 볼 수 있다.
데이터를 정제하기 이전, 데이터를 가공할 필요가 없는 median_house_value 데이터는 따로 빼둔다.
housing = strat_train_set.drop("median_house_value", axis=1) # drop labels for training set
housing_labels = strat_train_set["median_house_value"].copy()
이제 본격적으로 데이터를 정제해보도록 하자.
머신러닝 알고리즘을 위해 데이터를 준비한다.
데이터 정제(Data Cleaning)
누락된 특성(missing values, null values) 다루는 방법들 - 우리가 사용하는 데이터에선 'total_bedrooms' 특성만이 missing values가 존재했다!
- 해당 구역 제거 (행 제거)
- sample_incomplete_rows.dropna(subset=["total_bedrooms"])
- 해당 특성 제거 (열 제거)
- sample_incomplete_rows.drop("total_bedrooms", axis=1)
- 임의의 값으로 채움 (0, 평균, 중간값 등)
- median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True)
- median = housing["total_bedrooms"].median()
위의 작업같은 경우에도 또 한 번 친절한(!!) Scikit-learn에서는 SimpleImputer라는 클래스를 통해 기능을 제공하고 있다.
SimpleImputer를 사용해보자.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
위 같은 경우는 strategy를 median으로 설정해 null 값인 부분에 중위값으로 대신해서 채워넣는 작업을 한다.
그런데 SimpleImputer는 수치형 특성에만 작동이 되기 때문에 텍스트 특성은 제외하고 작업을 진행하여야 한다.
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
X = imputer.transform(housing_num)
# 이 때 X는 numpy array를 리턴하기 때문에 다시 pandas DataFrame으로 만들어 주어야 한다.
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing.index)
이제 null 값을 채운 데이터를 보면
housing_tr.loc[sample_incomplete_rows.index.values]

N/A로 표시되던 값들이 모두 중위값인 433으로 채워넣어진 모습을 확인할 수 있다.
Estimator, Transformer, Predictor
- 추정기(estimator)
- 데이터셋을 기반으로 모델 파라미터들을 추정하는 객체를 추정기라고 합니다(예를 들자면 imputer). 추정자체는 fit() method에 의해서 수행되고 하나의 데이터셋을 매개변수로 전달받습니다(지도학습의 경우 label을 담고 있는 데이터셋을 추가적인 매개변수로 전달)
- 변환기(transformer)
- (imputer같이) 데이터셋을 변환하는 추정기를 변환기라고 합니다. 변환은 transform() method가 수행합니다. 그리고 변환된 데이터셋을 반환합니다.
- 예측기(predictor)
- 일부 추정기는 주어진 새로운 데이터셋에 대해 예측값을 생성할 수 있습니다. 앞에서 사용했던 LinearRegression도 예측기입니다. 예측기의 predict() method는 새로운 데이터셋을 받아 예측값을 반환합니다. 그리고 score() method는 예측값에 대한 평가지표를 반환합니다.
텍스트와 범주형 특성 다루기
위 데이터 중 범주형 특성이 하나 있었다. 바로 'ocean_proximity'이다. 이 데이터는 어떻게 처리를 해야 모델에서 쉽게 처리할 수 있을까?
각 범주를 Numerical한 형태로 바꿔주면 Machine Learning Algorithm에 활용할 수 있을 것이다.
첫 번째 방법은 OrdinalEncoder를 사용하는 것이다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded[:10]
OrdinalEncoder는 카테고리들을에 대한 리스트를 생성했고, 그 리스트의 순서에 따라 값을 변환하는 즉, 0번째 자리에 있는 범주값은 0으로 변경하고 1번째 자리에 있는 범주값은 1로 변경하는... 굉장히 단순한 인코더인 것이다.
이 OrdianlEncoder에는 약간의 문제가 있다.
머신러닝 모델같은 경우에는 특성의 값이 비슷할수록 두 개의 샘플이 비슷하다는 것이 성립할 때 학습이 쉬워지게 된다. 그러나 위와 같은 경우에는 집이 바다에 얼마나 가까운지에 대한 속성인데 이 속성에 특징에 대해 전혀 분간을 즉, 어떤 집이 바다와 가까운지, 어떤 집이 바다와 가깝지 않은지에 대해 전혀 분간할 수 없게 된다. 이러한 문제점을 보완하기 위한 방법이 바로 One-hot encoding이다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
#One-hot encoding은 sparse matrix(하나의 값만 1이고 나머진 전부 0이기 때문에 공간 사용을 optimize하기 위해 저장한 특별한 형태)이기
#때문에 이를 보기 위해 다음과 같이 선언해준다.
housing_cat_1hot.toarray()
'''
#애초에 sparse option을 False로 주어 일반적인 Array로 생성해 보아도 된다.
cat_encoder = OneHotEncoder(sparse=False)
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
'''

나만의 변환기(Custom Transformers) 만들기
Scikit-Learn이 물론 유용한 변환기를 많이 제공하지만, 경우에 따라 특수한 데이터 처리 작업을 해야 할 경우가 많다. 이 때 나만의 변환기를 만들 수 있다.
반드시 구현해야 할 method들은 다음과 같다.
- fit()
- transform()
앞에서 우리는 feature들에 대한 조합으로 새로운 특성(rooms_per_household, population_per_household)을 만들어 보았다. 이 두 개의 새로운 특성을 데이터셋에 추가하는 작업을 해보도록 하자.
+) add_bedrooms_per_room(하이퍼 파라미터) = True로 주어지면 bedrooms_per_room 특성을 추가하자.
from sklearn.base import BaseEstimator, TransformerMixin
# column index
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
#housing.values라는 값을 사용해 Numpy Array를 넘겼다고 보면 된다. 즉, 위에서의 X는 Numpy Array 데이터라는 것이다.
housing_extra_attribs = attr_adder.transform(housing.values)
#위를 실행시킬 때 numpy array로 변환시켜 넘겼기 때문에 return된 값도 numpy array이다.
#이를 DataFrame으로 변환하기 위하여 다음의 코드를 실행시켜야 한다.
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()

특성 스케일링(Feature Scaling)
범위가 너무 넓은 특성을 특정 범위 내에 있도록 스케일링하는 작업이다. 특성 스케일링은 다음과 같은 것들이 있다.
- Min-max scaling : 0과 1사이 값이 되도록 조정
- 표준화(standardlization) : 평균 0, 분산 1이 되도록 만들어 준다.(Scikit-Learn의 StandardScaler)
변환 파이프라인(Transformation Pipelines)
여러 변환이 순차적으로 이뤄져야 할 경우 Pipeline class를 사용한다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
아까 위에서 null 값을 중위값으로 채워주는 작업,
새롭게 만든 변환기에서의 작업,
표준화작업 세 가지를 Pipeline이 한꺼번에 수행할 수 있도록 도와준다.
마지막 단계를 제외하고는 전부 fit_transform() method를 가지고 있어야 하기 때문에 꼭 변환기여야 한다. 마지막은 fit() method만 가지고 있어도 된다.
각 열마다 다른 파이프라인을 적용할 수도 있다.
가령, 수치형 특성과 범주형 특성들에 대해 별도의 변환이 필요하다면 ColumnTransformer를 사용하면 된다.
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
ColumnTransformer는 위의 Pipeline과는 달리 이름, 파이프라인, 파이프라인을 사용할 특성들의 리스트 총 세 가지를 전달해야 한다.
모델을 선택하고 훈련시킨다.
모델 훈련(Train a Model)
이제 본격적으로 모델을 훈련시켜 보도록 하자. 사용한 모델은 선형회귀모델이다.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
모델 훈련은 단 3줄이면 가능하다. 이제 몇 개 샘플에 모델을 적용해 예측값을 확인하고, 실제값과 비교해보자.
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(lin_reg.coef_, attributes), reverse=True)
왼쪽의 값은 학습한 계수의 값들이고, 오른쪽이 feature의 이름이다.
이 값이 클수록 집 값이 높은데에 더 높은 영향을 미친다는 것이다.
비교적 계수값이 작은 경우에는 반드시 영향이 없는 것일까? 반드시 그런 것은 아니다. 다른 특성들 가운데 겹치는 부분, 관련성이 많은 부분이 있을 수도 있다. 이러한 경우에는 그 특성들 모두가 중요하다 해서 모든 값들이 큰 값을 가지거나, 작은 값을 가지거나 그러지 않고 하나만 큰 값을 가지고 나머진 작은 값을 가진다는 등 나타날 수 있어 계수들의 크기만 갖고 중요하다 아니다라고 판단하는 것은 위험한 판단일 수 있다.
몇 개의 샘플에 대해 데이터 변환 및 예측을 해보도록 하자.
some_data = housing.iloc[:5] #raw data
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:", lin_reg.predict(some_data_prepared).round(decimals=1))
print("Labels:", list(some_labels))

첫 번째 값같은 경우는 실제값은 28만 예측값은 21만, 7만불정도 차이가 나는 경우를 볼 수 있다.
어떤 경우는 비슷하고, 어떤 경우는 빗나간 결과를 냈다는 것을 확인할 수 있다.
모델을 상세히 조정한다. (fine-tune your model)
전체 훈련 데이터셋에 대한 RMSE를 측정해보도록 하자.
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
7만불(대략 8천만원)정도가 평균적으로 에러가 나고 있다. 작은 에러라고 치부하고 넘어갈 수는 없을 것 같다. 게다가 테스트 데이터셋도 아니고 훈련 데이터셋에서 나는 에러라서... 우리가 적용한 모델에서 과소적합이 일어났음을 예상해볼 수 있을 것 같다... 왜 과소적합이 일어났을까?
우리는 몇 가지 근거를 생각해볼 수 있다.
- 특성들(features)이 충분한 정보를 제공하지 못했다.
- 모델이 충분히 강력하지 못했다.
우리는 두 번째 근거에 초점을 맞춰보도록 하겠다. 이번엔 강력한 비선형모델인 DecisionTreeRegressor를 사용해 보도록 하자.
잠깐 DecisionTreeRegressor가 뭔지 간단히 알아보도록 하자.
제일 위에 노드가 있다. 그 옆에 노드들이 있다. 이런 식으로 노드들 밑에 자식 노드들이 있는 우리들이 흔히 잘 아는 트리 구조이다.
그 노드 각각에는 Feature 이름이 주어진다. a라는 feature가 가장 위의 노드가 있다고 하면 들어온 데이터의 a와 일치하는 특성이 a에 정해진 특성 값보다 작으면 왼쪽 노드로 이동하게 된다.
다른 특성에도 마찬가지로 작으면 왼쪽, 크면 오른쪽 노드로 이동을 하다가 최종적으로 예측값을 return해내는 형태이다.
이러한 Tree를 만들어내는 과정이 모델의 학습 과정이다.
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
에러값이 0이 나왔다.
그렇다면 DecisionTreeRegressor 모델은 선형모델보다 나을까? 과대적합(Overfitting)이진 않을까?
나은지 낫지 않은지 어떻게 알 수 있을까?
- 테스트 데이터셋을 이용해 검증한다.
- (비추천) 이 방법은 테스트 데이터셋을 계속해서 들여다보게 되고, 계속 모델이 학습하는데 영향을 미치게 된다. 그렇게 되면 나중에 또 다른 테스트 데이터가 들어갈 때 그 데이터에 대해선 좋지 못한 가능성을 낼 확률이 높아지게 된다. 최대한 모델을 런칭하기 전까지 미루는 것이 낫다.
- 훈련 데이터셋의 일부를 검증데이터(validation data)셋으로 분리해 검증한다.
- k-겹 교차 검증(k-fold cross-validation)
교차 검증(Cross-Validation)을 사용한 평가
교차 검증이란 무엇일까? 예시를 통해 알아보도록 하자.
ex) 학습데이터를 5개로 쪼개고, 첫 번째 데이터를 제외하고 4개의 데이터로 훈련을 시킨다. 제외한 첫 번째 데이터에 대한 RMSE를 구하여 모델의 Performance를 낸다.
다음으론 두 번째 데이터를 제외하고 나머지 4개의 데이터로 훈련을 시킨다. 제외한 두 번째 데이터에 대한 RMSE를 구하여 모델의 Performance를 낸다.
이것을 마지막 다섯 번째 데이터까지 똑같이 반복한다.
최종적인 Performance의 값의 평균을 낸 값이 교차 검증을 통해 구할 수 있는 Error 값이다.
이제 교차 검증을 이용해서 모델에 대해 평가해보도록 하자.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
10개로 데이터를 나눴기 때문에 10개의 점수가 나왔다. 이 때 평균적인 에러값을 보니 71407...의 값이 나왔다. 아까의 0.0이 나왔던 모습과는 완전히 다른 결과가 나온 것이다. 즉, 위의 모델도 사용하지 않은 모델에 대해서는 좋지 않은 결과가 나온다는 것이다.
선형 모델의 평가는 다음과 같다.
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
DecisionTreeRegressor 모델보다 Mean 값이 즉 에러의 평균값이 작게 나온 것을 확인할 수 있다. 오히려 선형 모델이 새로운 데이터에 대해선 더 좋은 퍼포먼스를 낼 수 있을 것이라고 예측할 수 있는 것이다.
그렇다고 해서 선형 모델의 에러값이 작은 값은 아니기 때문에 모델에 대한 개선이 필요할 것 같다.
이번엔 RandomForestRegressor 모델을 이용해보도록 하자.
RandomForestRegressor도 아까 DecisionTreeRegressor처럼 트리 구조이다. 그러나 이 모델의 다른 점은 여러 개의 트리를 사용한다는 것이다. 각 트리의 개수만큼 prediction값들이 있을 것이다. 이 prediction의 값들을 모아 평균을 내 최종적인 prediction을 내는 모델이 바로 RandomForestRegressor이다.
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=100, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_rmse
from sklearn.model_selection import cross_val_score
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
에러들의 평균값이 5만 불 정도로 위의 두 모델보다 더 좋은 예측을 수행하고 있다는 사실을 예상할 수 있다.
모델 세부 튜닝(Fine-Tune Your Model)
우리는 이제 RandomForest 모델을 사용할 것으로 선택하였다.
그러나 선택 후에 모델을 세부적으로 튜닝하는 과정이 필요하다.
바로, 모델 학습을 위한 최적의 하이퍼파라미터를 찾는 과정이라고 할 수 있다.
그리드 탐색(Grid Search)
수동으로 하이퍼파라미터 조합을 시도하는 대신 GridSearchCV를 사용해보도록 하자.
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# then try 6 (2×3) combinations with bootstrap set as False
#bootstrap은 하나하나 일일이 해보는 것을 말한다.
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# train across 5 folds, that's a total of (12+6)*5=90 rounds of training
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
grid_search.best_params_
GridSearchCV의 결과로 8개의 특성을 사용하고, 30개의 트리의 개수가 가장 최적의 하이퍼파라미터라는 결과가 나왔다.
위에서 다양한 조합을 사용했을 때 학습한 결과도 확인할 수 있다.
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)

정말 좋은 방법이지만 우리가 일일이 하이퍼 파라미터의 조합을 정해주는 게 여간 귀찮은 일이 아니다. 이것을 또 개선하기 위하여 있는 좋은 방법이 바로 랜덤 탐색이다.
랜덤 탐색(Randomized Search)
하이퍼파라미터들이 가져야 하는 분포를 설정하고, 몇 가지 조합을 시도할 것인지 지정해주면 알아서 하이퍼 파라미터 조합을 만들어 내준다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200), #1에서 200 사이의 값을 uniform하게 샘플링
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
10번을 지정해 10가지 조합이 시도된 것을 확인할 수 있다.
위와 같은 경우에는 max_features가 7이고 n_estimators가 180일 때 가장 좋은 결과가 나타난다는 것을 확인할 수 있다.
특성 중요도, 에러 분석
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
#cat_encoder = cat_pipeline.named_steps["cat_encoder"] # old solution
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)
RandomForest 모델에 따면 가장 중요한 특성은 median income이고, 다음은 범주형 특성을 one-hot encoding으로 변환해준 데이터가 중요하다는 것을 알 수 있다.
테스트 데이터셋으로 최종 평가하기
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
마지막으로 얻어진 에러값은 47730이 나오는 것을 확인할 수 있다. 결과가 마음에 들면 론칭할 수 있고, 마음에 들지 않으면 개선(데이터를 더 구한다 / 데이터를 정제한다 / 다른 모델을 사용한다 / etc)을 해야할 것이다...
론칭, 모니터링, 시스템 유지 보수
상용환경에 배포하기 위해서는 데이터 전처리와 모델의 예측이 포함된 파이프라인을 만들어 저장하는 것이 좋다.
full_pipeline_with_predictor = Pipeline([
("preparation", full_pipeline),
("linear", LinearRegression())
])
my_model = full_pipeline_with_predictor
import joblib
joblib.dump(my_model, "my_model.pkl")
#...
my_model_loaded = joblib.load("my_model.pkl")
my_model_loaded.predict(some_data)
.pkl 파일로 모델을 저장해 배포할 수 있다. 저 모델 파일만 있으면 다른 환경에서 모델을 읽어들일 때, load함수만 사용하여 읽어들일 수 있다. 그 후 변환되지 않은 데이터가 주어졌을 때 한 번의 실행으로 데이터 변환부터 예측까지 모두 수행해 줄 수 있다.
론칭후 시스템 모니터링
- 시간이 지나면 모델이 낙후되면서 성능이 저하될 수 있기 때문에 모니터링 프로그램을 미리 구축해 놓는 것이 좋다.
- 자동모니터링
- ex) 추천시스템의 경우, 추천된 상품의 판매량이 줄어드는지?
- 수동모니터링
- ex) 이미지 분류의 경우, 분류된 이미지들 중 일부를 전문가에게 검토시킴
- 결과가 나빠진 경우
- 데이터 입력의 품질이 나빠졌는지, 센서가 고장났는지, 트렌드가 변화했는지, 계절적 요인이 있는지 등 문제점에 대해 파악해야 한다.
유지보수
- 정기적으로 새로운 데이터(레이블)를 수집해야 한다.
- 새로운 데이터를 테스트 데이터로, 현재의 테스트 데이터는 학습데이터로 편입한다.
- 다시 학습후, 새로운 테스트 데이터에 기반해 현재 모델과 새 모델을 평가하고 비교한다.

모든 프로세스에 골고루 시간을 배분해야 좋은 모델이 만들어 질 수 있다.
'AI > KDT 인공지능' 카테고리의 다른 글
| [06/15] 분류문제 실습 (0) | 2021.06.15 |
|---|---|
| 오토인코더, t-SNE (0) | 2021.06.14 |
| [05/18] Django로 동적 웹페이지 만들기 (0) | 2021.05.18 |
| [05/17] Web Application with Django (0) | 2021.05.17 |
| [05/12] EDA mini project (0) | 2021.05.12 |