Flask
Python 기반 마이크로 웹 프레임 워크
작지만, essential한 기능은 다 있다.
가상환경 설치하기
가상환경 설치
pip install virtualenv
가상환경 생성
virtualenv <가상환경 이름>
가상환경 진입
source <가상환경 이름>/bin/activate -> Macos의 경우
.\venv\Scripts\activate.bat -> Windows의 경우
가상환경 진입 후 pip freeze를 해보면 아무런 라이브러리도 설치가 되어 있지 않음을 확인할 수 있다. 즉, 독립적이란 것을 알 수 있다.
Flask를 이용해 웹 브라우저를 통해 Hello World 제공받기!
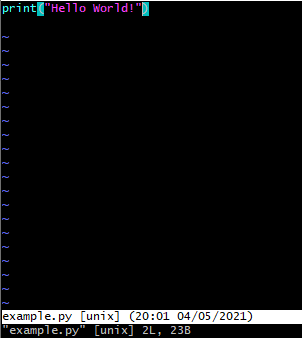
가상환경을 만든 폴더에 다음과 같은 app.py를 생성한다.

이를 실행하게 되면 다음과 같은 결과가 나타나게 되는데

이 때 나타난 웹 사이트 주소로 들어가게 되면 다음과 같이 "Hello World!"란 문구가 나타나 있는 사이트가 뜬다.

인터넷과 웹
인터넷(Internet)
전 세계 컴퓨터를 하나로 합치는 거대한 통신망
/
웹(Web)
인터넷에 연결된 사용자들이 정보를 공유할 수 있는 공간
웹에 있는 개개의 정보는 웹페이지
웹페이지의 집합은 웹사이트
웹은 클라이언트(정보 요청자)와 서버(정보 제공자) 사이의 소통이다.
웹 동작방식
- Client가 Server에 정보를 요청한다. = Request
- Server는 이 요청받은 정보에 대한 처리를 진행한다. (웹 페이지에 요청한 정보를 렌더링하여 제공)
- Server가 Client에게 요청에 대해 응답한다. = Response
요청을 하고, 응답을 하는 과정에서 사람들마다 정보를 제공하는 형식이 제각각이라면 인터넷을 사용하고 웹을 구현하기 어려울 것이다.
그래서 웹을 사용하는 사람들끼리의 약속을 했는데 그것이 바로 HTTP이다.
즉, 웹은 HTTP Request와 HTTP Response를 통해 동작하게 된다.
REST API
API란? 프로그램들이 서로 상호작용하는 것을 도와주는 매개체
REST(Representational State Transfer)란? 웹 서버가 요청을 응답하는 방법론 중 하나. 데이터가 아닌, 자원(Resource)의 관점으로 접근
HTTP URI(웹 상에 정보를 보낼 때 보낼 위치 식별자)를 통해 자원을 명시하고 HTTP Method(GET POST PUT 등)를 통해 해당 자원에 대한 CRUD를 진행
REST API의 Stateless(무상태성)
Client의 Context를 서버에서 유지하지 않는다. 각각의 Request를 독립적으로 관리한다.
Coffee shop REST API 구축해보기
from flask import Flask, jsonify, request
# jsonify는 딕셔너리 타입을 json타입으로 변환하는 것
# request는 HTTP request를 다룰 수 있는 모듈
app = Flask(__name__)
menus = [
{"id" : 1, "name" : "Espresso", "price" : 3800},
{"id" : 2, "name" : "Americano", "price" : 4100},
{"id" : 3, "name" : "CafeLatte", "price" : 4600}
]
@app.route('/')
def hello_flask():
return "Hello World!"
# GET /menus 자료를 가지고 온다.
@app.route('/menus')
def get_menus():
return jsonify({"menus" : menus})
# POST /menus 자료를 자원에 추가한다.
@app.route('/menus', methods=['POST'])
def create_menu(): # request가 JSON이라고 가정
# 전달받은 자료를 menus 자원에 추가
request_data = request.get_json() # {"name" : ..., "price" : ...}
new_menu = {
"id" : 4,
"name" : request_data['name'],
"price" : request_data['price']
}
menus.append(new_menu)
return jsonify(new_menu)
if __name__ == '__main__':
app.run()
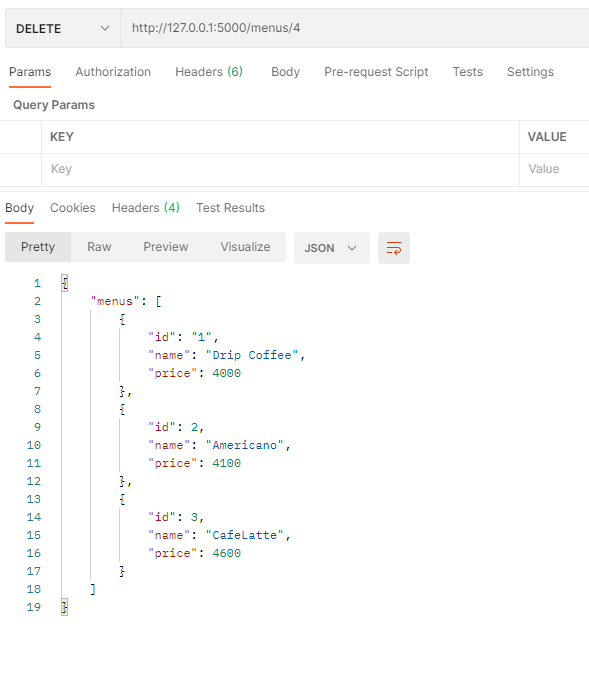
GET /menus 실행 결과 (READ)

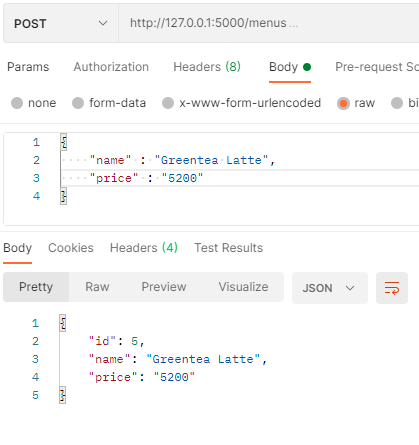
POSTMAN(API 테스트 툴)을 사용해 POST /menus 실행 결과 (CREATE)

Body 탭에 raw 데이터를 선택해 전송할 데이터를 입력해주고, JSON 타입으로 변경해서 Send하면 다음과 같은 결과가 나온다.

원하는 결과가 제대로 나오는 것을 확인할 수 있다. 데이터를 추가해주었으니 이후에 GET을 해주어 결과를 확인하면

다음과 같이 추가한 데이터가 잘 들어가 있음을 확인할 수 있다.
우리는 위 과정을 통해 CRUD 중 C(Create)와 R(Read)을 구현했다.
U(Update)와 D(Delete)도 마저 구현해보자!
from flask import Flask, jsonify, request
app = Flask(__name__)
menus = [
{"id" : 1, "name" : "Espresso", "price" : 3800},
{"id" : 2, "name" : "Americano", "price" : 4100},
{"id" : 3, "name" : "CafeLatte", "price" : 4600}
]
@app.route('/')
def hello_flask():
return "Hello World!"
# GET /menus 자료를 가지고 온다.
@app.route('/menus')
def get_menus():
return jsonify({"menus" : menus})
# POST /menus 자료를 자원에 추가한다.
@app.route('/menus', methods=['POST'])
def create_menu(): # request가 JSON이라고 가정
# 전달받은 자료를 menus 자원에 추가
request_data = request.get_json() # {"name" : ..., "price" : ...}
new_menu = {
"id" : len(menus)+1,
"name" : request_data['name'],
"price" : request_data['price']
}
menus.append(new_menu)
return jsonify(new_menu)
# PUT /menus/id 해당하는 id에 해당하는 데이터를 갱신한다.
@app.route('/menus/<id>', methods=['PUT'])
def update_data(id):
request_data=request.get_json()
request_data["id"]=id
for i in range(len(menus)):
if menus[i]["id"]==int(id):
menus[i]=request_data
return jsonify({"menus" : menus})
# DELETE /menus/id 해당하는 id에 해당하는 데이터를 삭제한다.
@app.route('/menus/<id>', methods=['DELETE'])
def delete_data(id):
print(id)
for i in range(len(menus)):
if menus[i]["id"]==int(id):
menus.pop(i)
return jsonify({"menus" : menus})
if __name__ == '__main__':
app.run()PUT/menus 실행 결과 (UPDATE)

DELETE/menus 실행 결과 (DELETE)
Coffee shop REST API 구축해보기 With Database
지금까지 코딩을 통해 사이트가 우리가 원하는 방식으로 잘 작동하는 것처럼 느껴질 수도 있다.
그러나 서버를 껐다키고 오면 정보가 사라지는 불상사가 생길 수도 있다. 이를 방지하기 위해선 데이터만을 보관하는
데이터베이스를 활용하여 Flask에 연동해 사용하도록 하자.
Flask-SQLAlchemy를 사용하였다.
참고 사이트
flask-sqlalchemy.palletsprojects.com/en/2.x/queries/
lowelllll.github.io/til/2019/04/19/TIL-flask-sqlalchemy-orm/
model.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import os
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
dbfile = os.path.join(basedir, 'db.sqlite')
app.config['SQLALCHEMY_DATABASE_URI'] ='sqlite:///'+dbfile
db = SQLAlchemy(app)
class Menu(db.Model):
__tablename__="Menu"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(32), nullable=False)
price = db.Column(db.Integer, nullable=False)
primary key인 int형 id 속성과
String형 name과 int형 price 속성을 갖고 있는
Menu 테이블을 선언 후,
cmd 내에서 model.py를 생성한 디렉토리로 이동하여 파이썬 커널로 적용시켜준 후 다음을 적용시켜주었다.
from Model import db
db.create_all()
menu1 = Menu(id = 1, name = "Espresso", 3800)
menu2 = Menu(id = 2, name = "Americano", 4100)
menu3 = Menu(id = 3, name = "CafeLatte", 4600)
db.session.add(menu1)
db.session.add(menu2)
db.session.add(menu3)
db.session.commit()
db.create_all()을 통해 실제 테이블을 생성하고,
데이터베이스에 넣을 데이터들을 선언해주고
db.session.add(menu1)
...
을 통해 테이블 내 데이터를 삽입하여
db.session.commit()을 통해 변경 사항을 적용시킨다.
app.py
from flask import Flask, jsonify, request
from model import db
from model import Menu
from model import app
@app.route('/')
def hello_flask():
return "Hello World!"
@app.route('/menus')
def get_menus():
menus = Menu.query.all() # Menu 테이블 내 모든 행 가져오기
m_list = [] # 가져온 menu obj들을 담을 리스트 선언
for menu in menus:
m_list.append({"id":menu.id, "name":menu.name,"price":menu.price})
return jsonify({"menu" : m_list})
@app.route('/menus', methods=['POST'])
def create_menu():
request_data = request.get_json()
menus = Menu.query.all()
new_menu = Menu(id = len(menus)+1, name = request_data['name'],price = request_data['price'])
db.session.add(new_menu) # 행 추가
db.session.commit() # 변경사항 적용
return {"id":len(menus)+1, "name":request_data['name'], "price":request_data['price']}
@app.route('/menus/<id>', methods=['PUT'])
def update_data(id):
request_data=request.get_json()
menu = db.session.query(Menu).filter(Menu.id==int(id)).first() # URL에 적힌 id와 Menu 테이블 내 행들 중 id가 일치하는 행 갖고 오기
menu.name = request_data['name'] # 갖고 온 행의 속성 값 변경
menu.price = request_data['price']
db.session.commit()
return get_menus()
@app.route('/menus/<id>', methods=['DELETE'])
def delete_data(id):
menu = db.session.query(Menu).filter(Menu.id==int(id)).first()
db.session.delete(menu) # 갖고 온 행 삭제
db.session.commit()
return get_menus()
if __name__ == '__main__':
app.run()
GET /menus 실행 결과 (READ)

POST /menus 실행 결과 (CREATE)

PUT/menus 실행 결과 (UPDATE)

DELETE/menus 실행 결과 (DELETE)

데이터베이스를 적용하지 않았을 때와 유사한 결과가 나온다는 것을 확인할 수 있지만 서버를 껐다 다시 시작해도 데이터가 사라지지 않고 온전히 남아있다는 중요한 사실을 알 수 있다.
'AI > KDT 인공지능' 카테고리의 다른 글
| [05/12] 데이터 씹고 뜯고 맛보고 즐기기 - EDA (0) | 2021.05.11 |
|---|---|
| [05/11] AWS를 활용한 인공지능 모델 배포 (0) | 2021.05.11 |
| [05/06] Matplotlib (0) | 2021.05.06 |
| [05/05] 데이터 다루기 - Pandas (0) | 2021.05.05 |
| [05/04] Git이란 무엇인가? (0) | 2021.05.04 |