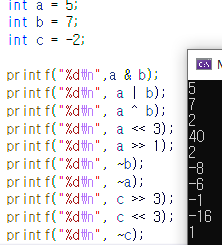
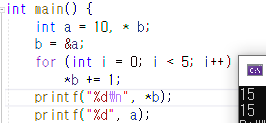증가값같은 경우는 무조건 최종값에 대한 조건이 충족하고 그 이후 조건식이 실행된 후에 증가값만큼 증가한다.
따라서 아무리 단항연산자(++, -- 같은)의 순서가 달라도 결과는 같다.
while문
do~while문
do{
조건이 참일 시 실행 문장;
}while(조건);
break, continue
break : switch문이나 반복문 안에서 break가 나오면 블록을 벗어남.
continue
continue 이후의 문장을 실행하지 않고 제어를 반복문의 처음으로 옮긴다.
반복문에서만 사용
배열과 문자열
1차원 배열
C언어
Java
public class Example {
public static void main(String[] args){
int a[] = new int[5];
int i;
for(i=0;i<5;i++)
a[i]=i+10;
for (i=0;i<5;i++)
System.out.printf("%d ", a[i]);
}
}
/*10 11 12 13 14*/
배열 초기화
char a[3] = {'A','B','C'}
int a[2][4] = {{1,2,3,4},{5,6,7,8}}
int a[3] = {3, } => 나머지 요소엔 0이 입력됨.
포인터
포인터란? 변수의 주소.
포인터의 용도
연결된 자료 구조 구성
동적으로 할당된 자료 구조 지정
배열을 인수로 전달
문자열을 표현
커다란 배열에서 요소를 효율적으로 저장
메모리에 직접 접근
사용자 정의 함수
Java의 클래스와 메소드
클래스 : 객체 생성을 위한 속성과 함수를 정의하는 설계도
class Human{
String name;
boolean sex;
int age;
}
public class Ex{
public static void main(String[] args)}
Human human = new Human(); //객체 생성
human.name = 'Cheolsu';
human.sex = True;
human.age = 17;
}
}
Python의 기초
# 기본 문법
# 변수 자료형 선언 안 해도 됨. 세미콜론 안 적어도 됨.
# 변수 연속 선언 가능
a = 1
b, c = 2, 3
# if나 for와 같이 코드 블록을 포함하는 명령문을 사용할 땐 indent(들여쓰기)를 맞춰줘야 함.
# 기본 indent는 4칸.
if b > a:
print("b가 a보다 큼")
strA = input('입력하세요') # 화면에 '입력하세요'란 문구 출력. 입력값 받을 때까지 커서 깜박임.
strB, strC = input().split(',') # 'hello,world'를 입력했으면 분리 문자 ','에 의해 strB에는 hello가, strC에는 world가 저장됨.
print(strB, strC, sep='/', end='.') # hello/world.
print('%-8.2f' % 200.20) # 200.20** (*은 공백) # 서식 문자열을 출력할 때 나타내는 표현
# % : 서식 문자임을 지정
# - : 왼쪽부터 출력
# 8 : 출력 자릿수를 8자리로 지정
# 2 : 소수점 이하를 2자리로 지정
# f : 실수로 지정
# python 문자열
print('abc'.upper()) # 'ABC' # 다 대문자로
print('ABC'.lower()) # 'abc' # 다 소문자로
print('ABC EFG'.capitalize()) # 'Abc efg' # 맨 첫 글자만 대문자. 나머진 소문자
print('ABC EFG'.title()) # 'Abc Efg' # 단어 첫 글자는 대문자. 나머진 소문자
print('abc'.replace('a','d')) # 'dbc' # 글자 대체
print('ABC-EFG'.split('-')) # ['ABC,'EFG'] # 분리 단어에 따라서 분리
print('abbbcd'.count('b')) # 3 # 글자 갯수 반환
print('abcd'.find('b')) # 1 # 값 위치 반환 # 찾지 못할 경우 -1 반환
print('abcd'.index('b')) # 1 # 값 위치 반환 # 찾지 못할 경우 오류 반환
lst = [0, 1, 2] # 1차원 리스트
llst = [[0, 1], [2, 3]] # 2차원 리스트
# 리스트 관련 주요 메소드
lst.append(4) # lst = [0, 1, 2, 4]
lst.insert(3, 3) # lst = [0, 1, 2, 3, 4] # 3번째 위치에 3을 추가
lst.insert(2, 5) # lst = [0, 1, 5, 2, 3, 4] # 2번째 위치에 5 추가
del lst[2] # lst = [0, 1, 2, 3, 4] # 2번째 요소 5 삭제
lst.remove(4) # lst = [0, 1, 2, 3] # lst에서 '4' 요소 찾아 삭제
lst.pop(1) # 3 # lst = [0, 2, 3] # 해당 위치에 있는 값 출력하고 해당 요소 삭제
lst.index(0) # 0 # 저장된 요소 위치 반환
[1, 0, 1, 0, 0].count(0) # 3 # 0 요소 개수 반환
[1, 2].extend([3, 4]) # [1, 2, 3, 4] # 리스트 끝에 새로운 리스트 추가하여 확장
[1, 2, 3].reverse() # [3, 2, 1] # 리스트 순서 역순으로 뒤집음
[2, 1, 3].sort() # [1, 2, 3] # 오름차순 정렬
[2, 1, 3].sort(reverse=True) # [3, 2, 1] # 내림차순 정렬
a = [1, 2, 3]
b = a.copy() # 리스트 복사 # 요소 값만 복사되어 서로 독립적인 메모리 공간 차지
for i in range(0, 10, 2): # 0에서 10-1까지 2만큼 증가하며 숫자 생성
print(i, end=' ') # 0, 2, 4, 6, 8
a = [1, 2, 3, 4, 5]
print(a[:3]) # 1, 2, 3 # 3-1까지의 요소 반환
print(a[0:4:2]) # 1, 3
python class
라이브러리
라이브러리 : 자주 사용하는 함수나 데이터들을 미리 만들어 모아 놓은 집합체
C언어 대표 표준 라이브러리
stdio.h : 데이터 입 * 출력에 사용되는 기능 제공
math.h : 수학 함수 제공
string.h : 문자열 처리에 사용되는 기능 제공
stdlib.h : 자료형 변환, 난수 발생, 메모리 할당에 사용되는 기능 제공
time.h : 시간 처리에 사용되는 기능 제공
Java 대표 표준 라이브러리
java.lang : 자바에 기본적으로 필요한 인터페이스, 자료형, 예외 처리 등에 관련된 기능 제공. import문 없이 사용 가능
java.util : 날짜 처리, 난수 발생, 복잡한 문자열 처리 등과 관련 기능 제공
java.io : 파일 입*출력과 관련된 기능 및 프로토콜 제공
java.net : 네트워크와 관련된 기능 제공
java.awt : 사용자 인터페이스(UI)와 관련된 기능 제공
Python 대표 표준 라이브러리
내장 함수 : import문이나 클래스명 없이 사용가능한 기본 인터페이스
os : 운영체제와 상호 작용하기 위한 기능 제공
re : 고급 문자열 처리 위한 기능 제공
math : 복잡한 수학 연산을 위한 기능 제공
random : 무작위 선택을 위한 기능 제공
statistics : 통계값 산출을 위한 기능 제공
datetime : 날짜와 시간 조작을 위한 기능 제공
절차적 프로그래밍 언어
일련의 처리 절차를 정해진 문법에 따라 순차적으로 기술해 나가는 언어
장점 : 빠른 실행 속도, 같은 코드를 복사하지 않고 다른 위치에서 호출해 사용가능, 모듈 구성 용이, 구조적 프로그래밍 가능
단점 : 여러운 프로그램 분석, 어려운 유지 보수 및 코드 수정
종류
C
데니스 리치에 의해 개발됨
자료 주소 조작 가능한 포인터 제공
고급 + 저급 프로그램 언어 특징
컴파일러 방식
이식성이 좋아 기종 관계없이 프로그램 작성 가능
ALGOL
수치 계산이나 논리 연산을 위한 과학 기술 계산용 언어
COBOL
사무 처리용 언어
FORTRAN
과학 기술 계산용 언어
객체 지향 프로그래밍 언어
객체 지향 프로그래밍 언어는 객체들을 조립해 프로그램을 작성할 수 있도록 한 프로그래밍 기법.
장점
상속을 통한 재사용과 시스템 확장 용이
코드 재활용성이 높음
자연적 모델링에 의해 분석과 설계를 쉽고 효율적으로 할 수 있음
사용자와 개발자 사이의 이해를 쉽게 해줌
대형 프로그램 작성 용이
소프트웨어 개발 및 유지보수가 용이
단점
정형화된 분석 및 설계 방법이 없음
구현 시 처리 시간 지연
종류
Java
분산 네트워크 환경에 적용 가능. 멀티스레드 기능을 제공해 여러 작업을 동시에 처리 가능
운영체제 및 하드웨어에 독립적이며 이식성이 강함
캡슐화가 가능하고 재사용성이 높음
C++
C언어에 객체지향 개념을 적용한 언어.
모든 문제를 객체로 모델링해 표현
Smalltalk
최초로 GUI를 제공한 언어
구성 요소
객체 : 데이터 + 메소드를 결합시킨 실체
데이터 : 객체들이 갖고 있는 데이터 값들을 단위별로 정의하는 것
메소드 : 객체가 메세지를 받아 실행해야 할 때 구체적 연산을 정의하는 것
클래스 : 두 개 이상의 유사한 객체들을 묶어서 하나의 공통된 특성을 표현하는 요소. 즉, 공통된 특성과 행위를 갖는 객체의 집합
메시지 : 객체들 간 상호작용 하는데 사용되는 수단
특징
캡슐화 : 데이터와 데이터를 처리하는 함수를 하나로 묶는 것
정보 은닉 : 다른 객체에 자신의 정보를 숨기고 자신의 연산만을 통해 접근을 허용하는 것
추상화 : 불필요한 부분을 생략하고 객체의 속성 중 가장 중요한 것에만 중점을 두어 모델화하는 것
상속성 : 이미 정의된 부모 클래스의 모든 속성과 연산을 하위 클래스가 물려받는 것.
다형성 : 하나의 메세지에 대해 각 클래스가 갖고 있는 고유한 방법으로 응답할 수 있는 능력
스크립트 언어
HTML 문서 안에 직접 프로그래밍 언어를 삽입해 사용하는 것.
기계어로 컴파일 되지 않고 별도의 번역기가 소스를 분석해 동작하게 하는 언어.
장점
컴파일 없이 바로 실행해 결과를 바로 확인 가능
배우고 코딩하기 쉬움
개발 시간이 짧음
소스 코드를 쉽고 빠르게 수정할 수 있음
단점
코드를 읽고 해석해야 해 실행 속도가 느림
런타임 오류가 많이 발생
종류
자바 스크립트
클라이언트용 스크립트 언어
웹 페이지 동작 제어, 변수 선언 필요 없음.
ASP
서버 측에서 동적으로 수행되는 페이지를 만들기 위한 언어
JSP
Java로 만들어진 서버용 스크립트 언어.
PHP
서버용 스크립트 언어.
C, Java 등과 문법이 유사해 배우기 쉬워 웹 페이지 제작에 많이 사용
파이썬
객체지향 기능을 지원하는 대화형 인터프리터 언어. 플랫폼에 독립적이고 문법이 간단함.
선언형 언어
프로그램이 수행해야 할 문제를 기술하는 언어. 목표를 명시하고 알고리즘은 명시하지 않는다.
함수형 언어
수학적 함수를 조합해 문제를 해결하는 언어. 재귀 호출이 자주 이용됨. 병렬 처리에 유리.
LISP
논리형 언어
기호 논리학에 기반을 둔 언어. 반복문이나 선택문을 사용하지 않는 비절차적 언어
PROLOG
장점 : 가독성이나 재사용성이 좋음, 작동 순서를 구체적으로 작성하지 않아 오류가 적음, 프로그램 동작을 변경하지 않고도 관련 값 대체 가능
종류
HTML
인터넷 표준 문서인 하이퍼텍스트 문서를 만들기 위해 사용하는 언어
LISP
인공지능 분야에 사용되는 언어.
기본 자료 구조가 연결 리스트 구조. 재귀 호출 많이 사용
PROLOG
논리학을 기초로 한 고급 언어. 인공 지능 분야에서 논리적 추론이나 리스트 처리 등에 주로 사용
XML
기존 HTML의 단점을 보완해 웹에서 구조화된 폭넓고 다양한 문서들을 상호 교환할 수 있도록 설계된 언어.
Haskell
함수형 프로그래밍 언어. 부작용이 없음. 코드가 간결하고 에러 발생 가능성이 낮음.
예외 처리
예외 : 프로그램의 정상적 실행을 방해하는 조건이나 상태
이러한 예외가 발생했을 때 프로그래머가 해당 문제에 대비해 작성해 놓은 처리 루틴을 수행하도록 하는 것.
java 예외 객체
ClassNotFoundException : 클래스를 찾지 못한 경우
NoSuchMethodException : 메소드를 찾지 못한 경우
FileNotFoundException : 파일을 찾지 못한 경우
InterruptedIOException : 입*출력 처리가 중단된 경우
ArithmeticException : 0으로 나누는 등 산술 연산에 대한 예외가 발생한 경우
IllegalArgumentException : 잘못된 인자를 전달한 경우
NumberFormatException : 문자열을 숫자 형식으로 변환한 경우
ArrayIndexOutOfBoundsException : 배열의 범위를 벗어난 접근을 시도한 경우
NegativeArraySizeException : 0보다 작은 값으로 배열 크기를 지정한 경우
총 20640개의 데이터에서 16512개의 데이터가 훈련용, 4128개의 데이터가 테스트용으로 임의로 뒤섞여 분리되었다.
그러나 위 방법에는 문제점이 하나 있다. 바로, 테스트 데이터를 뽑아내는 작업을 한 번만 하게 되는 것이 아니라 여러 번 하게 될 가능성이 높다는 것이다. 예를 들어 새로운 데이터가 들어왔을 때 다시 한 번 훈련 데이터와 테스트 데이터로 나누고 싶은 경우가 생길 수도 있는데 이 때, 또 위의 함수를 사용한다면 이전 훈련 데이터에 속하던 데이터들이 테스트 데이터로 속하게 될 수도 있고 반대의 경우가 생기게 될 수도 있을 것이다. 그러나 우리가 원하는 것은 한 번 테스트 데이터였던 데이터들은 계속 테스트 데이터로 남는 것이다.
test_set_check에서 식별자가 들어왔을 때, crc32 함수를 해싱 함수로 사용하고, & 기호는 bitwise and function이다. 위의 0xffffffff 숫자는 (2^32)-1이다. 저렇게 하게 되면 2^32으로 나눈 나머지 값이 되는 것이다. 그래서 식별자가 들어오면 이 식별자를 가진 데이터가 테스트 데이터에 속하는지 속하지 않는지 True or False를 반환하게 된다.
이제 식별자가 될 column을 추가해주어 보도록 하자.
# 인덱스를 id로 추가
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
위의 방법에는 문제점이 있다. 왜냐하면 id가 되려면 id는 늘 일정히 유지를 해야 하는데 행 번호를 id로 쓰게 되면 나중에 데이터베이스가 update 되어 몇몇 데이터들은 사라질 수도 있고, 중간에 삽입이 될 수도 있고(이런 문제를 방지하기 위해선 늘 새로운 데이터는 뒤에 넣어주어야 한다는 제약이 생기게 되기도 한다.), ... 그렇게 되면 행 번호가 바뀌게 될 수도 있기 때문이다.
그래서 id를 만드는 데 안전한 feature들을 사용하도록 해야 한다.
# 경도와 위도를 사용한 식별자 생성
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
train_set.head()
위 데이터에서 가장 unique한 데이터인 지리적 속성을 사용해서 식별자를 생성할 수 있게 된다. id는 다음과 같은 새로운 column의 형태로 생성된다.
우리의 scikit-learn에서 친절하게도 기본적으로 제공되는 데이터분할 함수가 있다.
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
위 우리가 생성한 함수에서처럼 20퍼센트의 데이터를 test 데이터로 사용할 것이고, 훈련 데이터는 train_set에, 테스트 데이터는 test_set에 저장되게끔 할 것이다. 결과는 직접 생성한 함수와 같다. 그러나 이렇게 하게 되면 우리가 식별자를 잘 나눠주었음에도 불구하고 문제가 생길 수 있다. 예를 들어 얘기하자면, 투표가 있으면 남성과 여성의 투표 전체적 비율이 훈련 데이터와 테스트 데이터에도 잘 보존이 될 수 있도록 해야 공평한 테스트가 이뤄진다고 볼 수 있을 것이다. 그래서 이러한 경우를 위해서 우리는 계층적 샘플링(stratified sampling)을 한다.
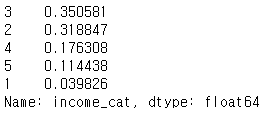
위 데이터의 경우에는 가장 중요한 특성인 'median income'의 분포가 훈련 데이터, 테스트 데이터에 잘 나타날 수 있도록 해보겠다.
housing["median_income"].hist()
위 데이터들을 그룹으로 나눠 연속적인 데이터에 범주형(categorical) 데이터로 변환해보도록 하자.
# Download the California image
images_path = os.path.join(PROJECT_ROOT_DIR, "images", "end_to_end_project")
os.makedirs(images_path, exist_ok=True)
#DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
DOWNLOAD_ROOT = "https://ko.wikipedia.org/wiki/%EC%BA%98%EB%A6%AC%ED%8F%AC%EB%8B%88%EC%95%84%EC%A3%BC#/media/%ED%8C%8C%EC%9D%BC:USA_California_location_map.svg"
filename = "california.png"
#나 같은 경우는 주석친 교수님이 주신 사이트에 캘리포니아 지도 이미지가 나타나지 않아 아래의 이미지를 따로 다운로드 받아 사용하였다...
import matplotlib.image as mpimg
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar()
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
save_fig("california_housing_prices_plot")
plt.show()
상관관계(Correlations) 관찰하기
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
# from pandas.tools.plotting import scatter_matrix # For older versions of Pandas
from pandas.plotting import scatter_matrix
# 특성 몇 개만 살펴봄
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
save_fig("scatter_matrix_plot")
여기서 median_house_value와 median_income 사이에서의 상관관계를 살펴보면
50만불에서의 데이터가 많이 모여있다는 사실을 알 수 있다. 우리는 이를 통해 집 값이 50만 불 이상으로 넘어가는 값들에 대해서는 딱 50만 불로 정제를 했을 것이라는 사실을 유추할 수 있다. 이런식으로 비정상적으로 보이는 데이터 같은 경우는 가능하면 traininig data에서 제거시켜주는 것이 모델 학습에 더 좋은 결과를 나타내어 줄 것이다.
우리는 다양한 특성들을 조합해서 실험을 해볼 수 있다.
가령, 가구당 방 개수가 평균적으로 몇 개일지,
침대방의 비율은 얼마나 될지,
가구당 인원은 얼마나 되는지 등에 대해서 있는 특성을 조합해 새로운 특성으로써 만들어 사용할 수 있다.
bedrooms per room같은 경우에는 하나의 집에서 침실이 차지하는 비율인데 집이 당연히 크면 클수록 침실로 쓸 방들은 제한이 되고, 다른 방들의 비율이 더 늘어날 것이다.
이 외에도 또다른 새로운 사실들을 많이 유추해 낼 수 있을 것이다.
이제는 실제로 모델에 데이터를 학습시키기 위하여 조금 더 데이터를 정제하는 작업을 거쳐보도록 하겠다.
데이터는 수동으로 변환하는 것보다 자동으로 변환하는 것에 대한 장점은 다음과 같다.
새로운 데이터에 대한 변환을 손쉽게 재생산(reproduce)할 수 있다.
향후에 재사용(reuse)할 수 있는 라이브러리를 구축할 수 있다.
실제 시스템에 가공되지 않은 데이터(raw data)를 알고리즘에 쉽게 입력으로 사용할 수 있도록 해준다.
여러 데이터 변환 방법을 쉽게 시도해 볼 수 있다.
데이터를 정제하기 이전, 데이터를 가공할 필요가 없는 median_house_value 데이터는 따로 빼둔다.
housing = strat_train_set.drop("median_house_value", axis=1) # drop labels for training set
housing_labels = strat_train_set["median_house_value"].copy()
이제 본격적으로 데이터를 정제해보도록 하자.
머신러닝 알고리즘을 위해 데이터를 준비한다.
데이터 정제(Data Cleaning)
누락된 특성(missing values, null values) 다루는 방법들 - 우리가 사용하는 데이터에선 'total_bedrooms' 특성만이 missing values가 존재했다!
median = housing["total_bedrooms"].median() sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True)
위의 작업같은 경우에도 또 한 번 친절한(!!) Scikit-learn에서는 SimpleImputer라는 클래스를 통해 기능을 제공하고 있다.
SimpleImputer를 사용해보자.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
위 같은 경우는 strategy를 median으로 설정해 null 값인 부분에 중위값으로 대신해서 채워넣는 작업을 한다.
그런데 SimpleImputer는 수치형 특성에만 작동이 되기 때문에 텍스트 특성은 제외하고 작업을 진행하여야 한다.
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
X = imputer.transform(housing_num)
# 이 때 X는 numpy array를 리턴하기 때문에 다시 pandas DataFrame으로 만들어 주어야 한다.
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing.index)
데이터셋을 기반으로 모델 파라미터들을 추정하는 객체를 추정기라고 합니다(예를 들자면 imputer). 추정자체는 fit() method에 의해서 수행되고 하나의 데이터셋을 매개변수로 전달받습니다(지도학습의 경우 label을 담고 있는 데이터셋을 추가적인 매개변수로 전달)
일부 추정기는 주어진 새로운 데이터셋에 대해 예측값을 생성할 수 있습니다. 앞에서 사용했던 LinearRegression도 예측기입니다. 예측기의 predict() method는 새로운 데이터셋을 받아 예측값을 반환합니다. 그리고 score() method는 예측값에 대한 평가지표를 반환합니다.
텍스트와 범주형 특성 다루기
위 데이터 중 범주형 특성이 하나 있었다. 바로 'ocean_proximity'이다. 이 데이터는 어떻게 처리를 해야 모델에서 쉽게 처리할 수 있을까?
각 범주를 Numerical한 형태로 바꿔주면 Machine Learning Algorithm에 활용할 수 있을 것이다.
OrdinalEncoder는 카테고리들을에 대한 리스트를 생성했고, 그 리스트의 순서에 따라 값을 변환하는 즉, 0번째 자리에 있는 범주값은 0으로 변경하고 1번째 자리에 있는 범주값은 1로 변경하는... 굉장히 단순한 인코더인 것이다.
이 OrdianlEncoder에는 약간의 문제가 있다.
머신러닝 모델같은 경우에는 특성의 값이 비슷할수록 두 개의 샘플이 비슷하다는 것이 성립할 때 학습이 쉬워지게 된다. 그러나 위와 같은 경우에는 집이 바다에 얼마나 가까운지에 대한 속성인데 이 속성에 특징에 대해 전혀 분간을 즉, 어떤 집이 바다와 가까운지, 어떤 집이 바다와 가깝지 않은지에 대해 전혀 분간할 수 없게 된다. 이러한 문제점을 보완하기 위한 방법이 바로 One-hot encoding이다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
#One-hot encoding은 sparse matrix(하나의 값만 1이고 나머진 전부 0이기 때문에 공간 사용을 optimize하기 위해 저장한 특별한 형태)이기
#때문에 이를 보기 위해 다음과 같이 선언해준다.
housing_cat_1hot.toarray()
'''
#애초에 sparse option을 False로 주어 일반적인 Array로 생성해 보아도 된다.
cat_encoder = OneHotEncoder(sparse=False)
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
'''
나만의 변환기(Custom Transformers) 만들기
Scikit-Learn이 물론 유용한 변환기를 많이 제공하지만, 경우에 따라 특수한 데이터 처리 작업을 해야 할 경우가 많다. 이 때 나만의 변환기를 만들 수 있다.
반드시 구현해야 할 method들은 다음과 같다.
fit()
transform()
앞에서 우리는 feature들에 대한 조합으로 새로운 특성(rooms_per_household, population_per_household)을 만들어 보았다. 이 두 개의 새로운 특성을 데이터셋에 추가하는 작업을 해보도록 하자.
+) add_bedrooms_per_room(하이퍼 파라미터) = True로 주어지면 bedrooms_per_room 특성을 추가하자.
from sklearn.base import BaseEstimator, TransformerMixin
# column index
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
#housing.values라는 값을 사용해 Numpy Array를 넘겼다고 보면 된다. 즉, 위에서의 X는 Numpy Array 데이터라는 것이다.
housing_extra_attribs = attr_adder.transform(housing.values)
#위를 실행시킬 때 numpy array로 변환시켜 넘겼기 때문에 return된 값도 numpy array이다.
#이를 DataFrame으로 변환하기 위하여 다음의 코드를 실행시켜야 한다.
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()
특성 스케일링(Feature Scaling)
범위가 너무 넓은 특성을 특정 범위 내에 있도록 스케일링하는 작업이다. 특성 스케일링은 다음과 같은 것들이 있다.
Min-max scaling : 0과 1사이 값이 되도록 조정
표준화(standardlization) : 평균 0, 분산 1이 되도록 만들어 준다.(Scikit-Learn의 StandardScaler)
비교적 계수값이 작은 경우에는 반드시 영향이 없는 것일까?반드시 그런 것은 아니다. 다른 특성들 가운데 겹치는 부분, 관련성이 많은 부분이 있을 수도 있다. 이러한 경우에는 그 특성들 모두가 중요하다 해서 모든 값들이 큰 값을 가지거나, 작은 값을 가지거나 그러지 않고 하나만 큰 값을 가지고 나머진 작은 값을 가진다는 등 나타날 수 있어 계수들의 크기만 갖고 중요하다 아니다라고 판단하는 것은 위험한 판단일 수 있다.
7만불(대략 8천만원)정도가 평균적으로 에러가 나고 있다. 작은 에러라고 치부하고 넘어갈 수는 없을 것 같다. 게다가 테스트 데이터셋도 아니고 훈련 데이터셋에서 나는 에러라서... 우리가 적용한 모델에서 과소적합이 일어났음을 예상해볼 수 있을 것 같다... 왜 과소적합이 일어났을까?
우리는 몇 가지 근거를 생각해볼 수 있다.
특성들(features)이 충분한 정보를 제공하지 못했다.
모델이 충분히 강력하지 못했다.
우리는 두 번째 근거에 초점을 맞춰보도록 하겠다. 이번엔 강력한 비선형모델인 DecisionTreeRegressor를 사용해 보도록 하자.
잠깐 DecisionTreeRegressor가 뭔지 간단히 알아보도록 하자.
제일 위에 노드가 있다. 그 옆에 노드들이 있다. 이런 식으로 노드들 밑에 자식 노드들이 있는 우리들이 흔히 잘 아는 트리 구조이다.
그 노드 각각에는 Feature 이름이 주어진다. a라는 feature가 가장 위의 노드가 있다고 하면 들어온 데이터의 a와 일치하는 특성이 a에 정해진 특성 값보다 작으면 왼쪽 노드로 이동하게 된다.
다른 특성에도 마찬가지로 작으면 왼쪽, 크면 오른쪽 노드로 이동을 하다가 최종적으로 예측값을 return해내는 형태이다.
그렇다면 DecisionTreeRegressor 모델은 선형모델보다 나을까? 과대적합(Overfitting)이진 않을까?
나은지 낫지 않은지 어떻게 알 수 있을까?
테스트 데이터셋을 이용해 검증한다.
(비추천) 이 방법은 테스트 데이터셋을 계속해서 들여다보게 되고, 계속 모델이 학습하는데 영향을 미치게 된다. 그렇게 되면 나중에 또 다른 테스트 데이터가 들어갈 때 그 데이터에 대해선 좋지 못한 가능성을 낼 확률이 높아지게 된다. 최대한 모델을 런칭하기 전까지 미루는 것이 낫다.
훈련 데이터셋의 일부를 검증데이터(validation data)셋으로 분리해 검증한다.
k-겹 교차 검증(k-fold cross-validation)
교차 검증(Cross-Validation)을 사용한 평가
교차 검증이란 무엇일까? 예시를 통해 알아보도록 하자.
ex) 학습데이터를 5개로 쪼개고, 첫 번째 데이터를 제외하고 4개의 데이터로 훈련을 시킨다. 제외한 첫 번째 데이터에 대한 RMSE를 구하여 모델의 Performance를 낸다.
다음으론 두 번째 데이터를 제외하고 나머지 4개의 데이터로 훈련을 시킨다. 제외한 두 번째 데이터에 대한 RMSE를 구하여 모델의 Performance를 낸다.
이것을 마지막 다섯 번째 데이터까지 똑같이 반복한다.
최종적인 Performance의 값의 평균을 낸 값이 교차 검증을 통해 구할 수 있는 Error 값이다.
DecisionTreeRegressor 모델보다 Mean 값이 즉 에러의 평균값이 작게 나온 것을 확인할 수 있다. 오히려 선형 모델이 새로운 데이터에 대해선 더 좋은 퍼포먼스를 낼 수 있을 것이라고 예측할 수 있는 것이다.
그렇다고 해서 선형 모델의 에러값이 작은 값은 아니기 때문에 모델에 대한 개선이 필요할 것 같다.
이번엔 RandomForestRegressor 모델을 이용해보도록 하자.
RandomForestRegressor도 아까 DecisionTreeRegressor처럼 트리 구조이다. 그러나 이 모델의 다른 점은 여러 개의 트리를 사용한다는 것이다. 각 트리의 개수만큼 prediction값들이 있을 것이다. 이 prediction의 값들을 모아 평균을 내 최종적인 prediction을 내는 모델이 바로 RandomForestRegressor이다.
데이터베이스란? 데이터를 저장하는 시스템. 특히, 구조화한다는 특징이 있다. 단순히 정보를 저장한다는 창고의 개념이 아니라 쉽게 정보를 탐색할 수 있게 정렬해두어 유저가 정보를 참조하고 싶을 때 바로 참조할 수 있는 시스템이다.
- Relational DB : 테이블 형태. row와 column으로 데이터를 관리하는 것.
- 데이터베이스 인터페이스 프로그래밍 언어 = SQL
- Django에는 ORM이 내장되어 있다.
models.py
class <모델 이름>(models.Model):
# field1 = models.FieldType()...
"""
문자열 : CharField
숫자 : IntegerField, SmallIntegerField, ...
논리형 : BooleanField
시간 / 날짜 : DateTimeField
"""
admin.py
from .models import <모델 이름>
admin.site.register(<모델 이름>)
다음과 같이 admin.py에 생성한 모델을 등록하여 주면
다음과 같이 관리자 홈페이지에서 모델을 관리할 수 있게 된다. 그러나 Coffee(<모델 이름>) 테이블을 눌러보면
그림 출처 : 프로그래머스 스쿨
아직은 반영이 되지 않은 것을 확인할 수 있다. 이를 반영시켜주기 위해선 migrate을 해주어야 한다.
장고에서는 데이터베이스를 관리할 때 모델을 git의 commit과 유사한 migration이란 단위로 관리하게 된다.
cmd에서 migrate를 진행해보도록 하자.
'''git add와 유사'''
> python manage.py makemigrations homepage
'''result'''
Migrations for 'homepage':
homepage\migrations\0001_initial.py
- Create model <모델 이름>
'''만들어진 migration들을 실제 DB에 반영'''
>python manage.py migrate
'''result'''
Operations to perform:
Apply all migrations: admin, auth, contenttypes, homepage, sessions
Running migrations:
Applying homepage.0001_initial... OK
위 작업 이후 다시 admin 사이트의 Coffee 테이블을 눌러서 확인하면
다음과 같이 정상적으로 페이지가 참조되는 것을 확인할 수 있다.
위 페이지에서 Object를 추가하면 다음과 같이 나타나게 된다.
<모델 이름> obejct(1),
<모델 이름> obejct(2), ...
굉장히 가독성이 떨어지는 이름으로 생성이 되게 된다.
무슨 Object를 지칭하는지 한 번에 알 수 있는 좋은 이름으로 각 Object가 생성되도록 하기 위해 코드를 수정해보도록 하자.
models.py
class <모델 이름>(models.Model):
def __str__(self):
return self.<객체를 대표하는 파라미터>
다음과 같이 설정을 해주고 다시 admin 사이트로 가서 확인을 하면
다음과 같이 각 객체를 잘 나타내어 주는 것을 확인할 수 있다.
Template에서 Model 확인하기
views.py
from .models import Coffee
def coffee_view(request):
coffee_all = Coffee.objects.all() #select * from Coffee랑 동일한 결과를 갖고 옴
return render(request, 'coffee.html',{"coffee_list":coffee_all})
from django import forms
from .models import Coffee
class CoffeeForm(forms.ModelForm): # ModelForm을 상속받는 CoffeeForm 생성
class Meta: #form을 만들기 위해 어떤 model을 써야 하는지 지정하게 됨
model = Coffee
fields = ('name', 'price', 'is_ice')
views.py
from .forms import CoffeeForm
def coffee_view(request):
coffee_all = Coffee.objects.all()
form = CoffeeForm() #Form 객체 생성
return render(request, 'coffee.html',{"coffee_list":coffee_all,"coffee_form":form})
form 태그 사이에 오직 {% csrf_token %}만 추가해주면 된다. 이를 추가해준 후에 Save 버튼을 누르면 아까와 같은 에러 사이트는 안 뜨고 정보가 전달이 된 것을 확인할 수 있다. 그러나 전달된 정보는 DB에 들어가지 않게 된다. 왜냐하면 view에서 POST 요청이 들어왔을 때 어떤 logic을 행해야 하는지에 대한 정보를 담지 않았기 때문이다.
view에서 POST 요청이 들어왔을 때 모델에 정보를 담아주는 logic을 구현해 보도록 하자.
views.py
def coffee_view(request):
coffee_all = Coffee.objects.all()
# 만약 request가 POST라면:
# POST를 바탕으로 Form을 완성하고
# Form이 유효하면 -> 저장!
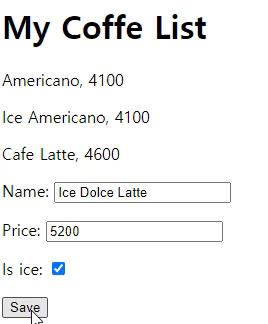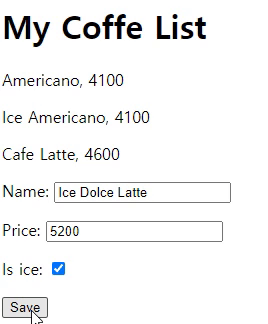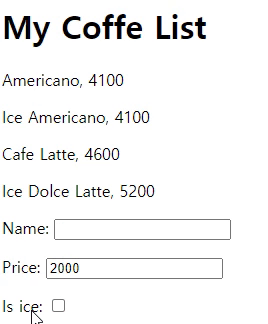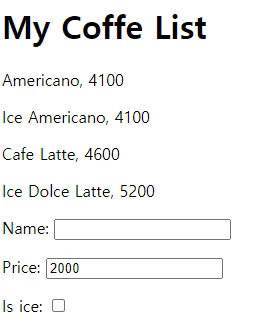
if request.method=='POST':
form = CoffeeForm(request.POST) # 완성된 Form
if form.is_valid(): # 채워진 Form이 유효하다면:
form.save() # 이 Form의 내용을 Model에 저장!
form = CoffeeForm()
return render(request, 'coffee.html',{"coffee_list":coffee_all,"coffee_form":form})